

Решение проблемы нехватки данных: S-CycleGAN для перевода КТ в ультразвук
Таблица ссылок
Резюме и 1 Введение
-
Связанные работы
-
Постановка проблемы
-
Методология
4.1. Дистилляция с учетом границы принятия решений
4.2. Консолидация знаний
-
Экспериментальные результаты и 5.1. Настройка эксперимента
5.2. Сравнение с методами SOTA
5.3. Исследование абляции
-
Заключение и будущая работа и Ссылки
\
Дополнительные материалы
- Детали теоретического анализа механизма KCEMA в IIL
- Обзор алгоритма
- Детали набора данных
- Детали реализации
- Визуализация запыленных входных изображений
- Больше экспериментальных результатов
Резюме
Инкрементное обучение на уровне экземпляров (IIL) фокусируется на непрерывном обучении с данными одних и тех же классов. По сравнению с инкрементным обучением на уровне классов (CIL), IIL редко исследуется, поскольку IIL меньше страдает от катастрофического забывания (CF). Однако, помимо сохранения знаний, в сценариях реального развертывания, где пространство классов всегда предопределено, непрерывное и экономически эффективное продвижение модели с потенциальной недоступностью предыдущих данных является более важным требованием. Поэтому мы сначала определяем новую и более практичную настройку IIL как повышение производительности модели помимо сопротивления CF только с новыми наблюдениями. В новой настройке IIL необходимо решить две проблемы: 1) печально известное катастрофическое забывание из-за отсутствия доступа к старым данным и 2) расширение существующей границы принятия решений для новых наблюдений из-за дрейфа концепции. Для решения этих проблем наше ключевое понимание заключается в умеренном расширении границы принятия решений для неудачных случаев при сохранении старой границы. Следовательно, мы предлагаем новый метод дистилляции с учетом границы принятия решений с консолидацией знаний для учителя, чтобы облегчить обучение ученика новым знаниям. Мы также устанавливаем эталоны на существующих наборах данных Cifar-100 и ImageNet. Примечательно, что обширные эксперименты демонстрируют, что модель учителя может быть лучшим инкрементным учеником, чем модель ученика, что опровергает предыдущие методы, основанные на дистилляции знаний, рассматривающие ученика как главную роль.
1. Введение
В последние годы для различных задач, таких как классификация изображений, сегментация и обнаружение, предлагаются многие отличные сети, основанные на глубоком обучении. Хотя эти сети хорошо работают на обучающих данных, они неизбежно терпят неудачу на некоторых новых данных, которые не обучены в реальном приложении. Непрерывное и эффективное повышение производительности развернутой модели на этих новых данных является важным требованием. Текущее решение переобучения сети с использованием всех накопленных данных имеет два недостатка: 1) с увеличением размера данных стоимость обучения каждый раз становится выше, например, больше часов GPU и больший углеродный след [20], и 2) в некоторых случаях старые данные больше недоступны из-за политики конфиденциальности или ограниченного бюджета для хранения данных. В случае, когда доступно или используется мало или нет старых данных, переобучение модели глубокого обучения с новыми данными всегда вызывает снижение производительности на старых данных, т.е. проблему катастрофического забывания (CF). Для решения проблемы CF предлагается инкрементное обучение [4, 5, 22, 29], также известное как непрерывное обучение. Инкрементное обучение значительно повышает практическую ценность моделей глубокого обучения и привлекает интенсивный исследовательский интерес.
\ 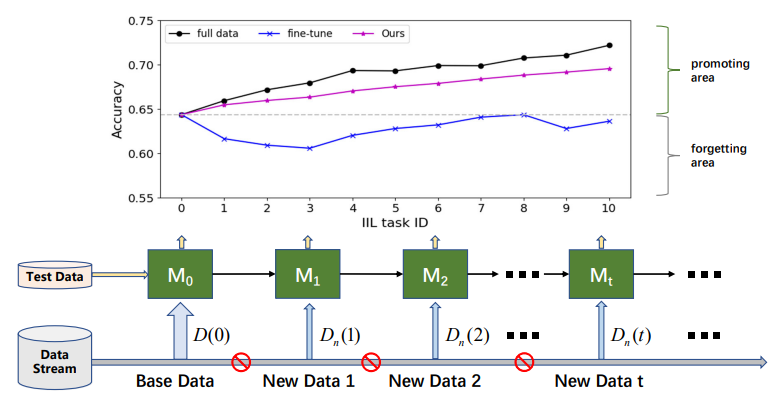
\ В зависимости от того, поступают ли новые данные из уже виденных классов, инкрементное обучение можно разделить на три сценария [16, 17]: инкрементное обучение на уровне экземпляров (IIL) [3, 16], где все новые данные принадлежат к уже виденным классам, инкрементное обучение на уровне классов (CIL) [4, 12, 15, 22], где новые данные имеют разные метки классов, и гибридное инкрементное обучение [6, 30], где новые данные состоят из новых наблюдений как из старых, так и из новых классов. По сравнению с CIL, IIL относительно мало исследован, поскольку он менее подвержен CF. Ломонако и Мальтони [16] сообщили, что тонкая настройка модели с ранней остановкой может хорошо справиться с проблемой CF в IIL. Однако этот вывод не всегда верен, когда нет доступа к старым обучающим данным, а новые данные имеют гораздо меньший размер, чем старые данные, как показано на рис. 1. Тонкая настройка часто приводит к сдвигу границы принятия решений, а не к ее расширению для размещения новых наблюдений. Помимо сохранения старых знаний, реальное развертывание больше беспокоится об эффективном продвижении модели в IIL. Например, при обнаружении дефектов промышленных продуктов классы дефектов всегда ограничены известными категориями. Но морфология этих дефектов меняется время от времени. Неудачи на этих невиданных дефектах должны быть своевременно и эффективно исправлены, чтобы избежать попадания дефектных продуктов на рынок. К сожалению, существующие исследования в основном сосредоточены на сохранении знаний о старых данных, а не на обогащении знаний новыми наблюдениями.
\ В этой статье, чтобы быстро и экономически эффективно улучшить обученную модель с новыми наблюдениями уже виденных классов, мы сначала определяем новую настройку IIL как сохранение изученных знаний, а также повышение производительности модели на новых наблюдениях без доступа к старым данным. Простыми словами, мы стремимся улучшить существующую модель, используя только новые данные, и достичь производительности, сопоставимой с моделью, переобученной со всеми накопленными данными. Новый IIL является сложным из-за дрейфа концепции [6], вызванного новыми наблюдениями, такими как изменение цвета или формы по сравнению со старыми данными. Следовательно, в новой настройке IIL необходимо решить две проблемы: 1) печально известное катастрофическое забывание из-за отсутствия доступа к старым данным и 2) расширение существующей границы принятия решений для новых наблюдений.
\ Для решения вышеуказанных проблем в новой настройке IIL мы предлагаем новую структуру IIL, основанную на структуре учитель-ученик. Предлагаемая структура состоит из процесса дистилляции с учетом границы принятия решений (DBD) и процесса консолидации знаний (KC). DBD позволяет модели ученика учиться на новых наблюдениях с осознанием существующих межклассовых границ принятия решений, что позволяет модели определить, где укрепить свои знания и где их сохранить. Однако граница принятия решений не отслеживается, когда вокруг границы недостаточно образцов из-за отсутствия доступа к старым данным в IIL. Чтобы преодолеть это, мы черпаем вдохновение из практики посыпания пола мукой для выявления скрытых следов. Аналогично, мы вводим случайный гауссовский шум для загрязнения входного пространства и проявления изученной границы принятия решений для дистилляции. Во время обучения модели ученика с дистилляцией границы обновленные знания дополнительно консолидируются обратно в модель учителя периодически и многократно с помощью механизма EMA [28]. Использование модели учителя в качестве целевой модели является новаторской попыткой, и ее осуществимость объясняется теоретически.
\ В соответствии с новой настройкой IIL мы реорганизуем обучающий набор некоторых существующих наборов данных, обычно используемых в CIL, таких как Cifar-100 [11] и ImageNet [24], для установления эталонов. Модель оценивается как на тестовых данных, так и на недоступных базовых данных на каждой инкрементной фазе. Наши основные вклады можно резюмировать следующим образом: 1) Мы определяем новую настройку IIL для поиска быстрого и экономически эффективного продвижения модели на новых наблюдениях и устанавливаем эталоны; 2) Мы предлагаем новый метод дистилляции с учетом границы принятия решений для сохранения изученных знаний, а также обогащения их новыми данными; 3) Мы творчески консолидируем изученные знания от ученика к модели учителя для достижения лучшей производительности и обобщаемости, и доказываем осуществимость теоретически; и 4) Обширные эксперименты демонстрируют, что предложенный метод хорошо накапливает знания только с новыми данными, в то время как большинство существующих методов инкрементного обучения потерпели неудачу.
\
:::info Эта статья доступна на arxiv под лицензией CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
:::info Авторы:
(1) Цян Не, Гонконгский университет науки и технологий (Гуанчжоу);
(2) Вэйфу Фу, Лаборатория Tencent Youtu;
(3) Юхуань Линь, Лаборатория Tencent Youtu;
(4) Цзялинь Ли, Лаборатория Tencent Youtu;
(5) Ифэн Чжоу, Лаборатория Tencent Youtu;
(6) Юн Лю, Лаборатория Tencent Youtu;
(7) Цян Не, Гонконгский университет науки и технологий (Гуанчжоу);
(8) Чэнцзе Ван, Лаборатория Tencent Youtu.
:::
\
Вам также может быть интересно

Виталик Бутерин представил двухэтапный план полной модернизации уровня исполнения Ethereum

Бутерин нацелился на основные узкие места Ethereum с помощью смелой модернизации
