Cài đặt IIL mới: Nâng cao mô hình đã triển khai chỉ với dữ liệu mới
Bảng liên kết
Tóm tắt và 1 Giới thiệu
-
Các công trình liên quan
-
Thiết lập vấn đề
-
Phương pháp luận
4.1. Chưng cất nhận thức ranh giới quyết định
4.2. Củng cố kiến thức
-
Kết quả thực nghiệm và 5.1. Thiết lập thí nghiệm
5.2. So sánh với các phương pháp SOTA
5.3. Nghiên cứu loại bỏ
-
Kết luận và công việc tương lai và Tài liệu tham khảo
\
Tài liệu bổ sung
- Chi tiết phân tích lý thuyết về cơ chế KCEMA trong IIL
- Tổng quan thuật toán
- Chi tiết bộ dữ liệu
- Chi tiết triển khai
- Hình ảnh trực quan của các hình ảnh đầu vào bị phủ bụi
- Thêm kết quả thực nghiệm
3. Thiết lập vấn đề
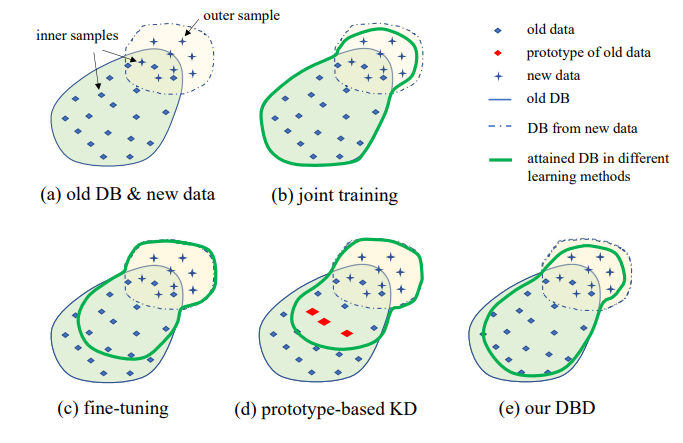
Minh họa về thiết lập IIL được đề xuất được thể hiện trong Hình 1. Như có thể thấy, dữ liệu được tạo ra liên tục và không thể dự đoán trong luồng dữ liệu. Nhìn chung trong ứng dụng thực tế, mọi người có xu hướng thu thập đủ dữ liệu trước và huấn luyện một mô hình mạnh M0 để triển khai. Dù mô hình mạnh đến đâu, nó cũng sẽ không thể tránh khỏi việc gặp phải dữ liệu ngoài phân phối và thất bại trên đó. Những trường hợp thất bại này và các quan sát mới có điểm số thấp khác sẽ được chú thích để huấn luyện mô hình theo thời gian. Việc huấn luyện lại mô hình với tất cả dữ liệu tích lũy mỗi lần dẫn đến chi phí thời gian và tài nguyên ngày càng cao hơn. Do đó, IIL mới nhằm mục đích nâng cao mô hình hiện có chỉ với dữ liệu mới mỗi lần.
\ 
\ 
\
:::info Tác giả:
(1) Qiang Nie, Đại học Khoa học và Công nghệ Hồng Kông (Quảng Châu);
(2) Weifu Fu, Phòng thí nghiệm Tencent Youtu;
(3) Yuhuan Lin, Phòng thí nghiệm Tencent Youtu;
(4) Jialin Li, Phòng thí nghiệm Tencent Youtu;
(5) Yifeng Zhou, Phòng thí nghiệm Tencent Youtu;
(6) Yong Liu, Phòng thí nghiệm Tencent Youtu;
(7) Qiang Nie, Đại học Khoa học và Công nghệ Hồng Kông (Quảng Châu);
(8) Chengjie Wang, Phòng thí nghiệm Tencent Youtu.
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Có thể bạn cũng thích

Alex Eala tranh huy chương vàng đơn tại SEA Games nhưng không phải đối đầu với Janice Tjen

Vitalik Buterin muốn làm cho thuật toán của X trở nên minh bạch bằng cách sử dụng ZK-proofs