

Оптимизация стоимости и использования кластера Databricks без системных таблиц

В большинстве корпоративных сред Databricks (таких как MSC или крупные аналитические экосистемы), системные таблицы, такие как system.jobrunlogs или system.cluster_events, могут быть ограничены или отключены из-за политик безопасности или управления.
Однако отслеживание использования кластера и затрат имеет решающее значение для:
- Понимания насколько эффективно задания используют вычислительные ресурсы
- Выявления простаивающих кластеров или утечек затрат
- Прогнозирования бюджета инфраструктуры
- Создания пользовательских панелей затрат
Этот блог демонстрирует пошаговый подход к расчету использования кластера и затрат с использованием только Databricks REST APIs — системные таблицы не требуются.
Вариант использования проекта
На нашей платформе данных MSC мы запускаем несколько кластеров Databricks в средах разработки, тестирования и production. \n У нас было три основные проблемы:
- Нет доступа к системным таблицам (ограничено политиками администратора)
- Временные кластеры для заданий, создаваемых динамически ADF или оркестровыми конвейерами
- Нет прямого представления о том, как использование кластера влияет на затраты
Поэтому мы создали легковесный анализатор использования, который:
- Извлекает данные из Databricks REST APIs
- Рассчитывает время выполнения задания по сравнению со временем работы кластера
- Оценивает затраты с использованием ставок DBU и VM
- Выводит удобный для использования DataFrame
Проблема и подход
Выявленная проблема
Командам часто необходимо знать:
- Какие кластеры простаивают (работают с низкой активностью заданий)?
- Каков процент использования (время выполнения задания по сравнению с временем работы кластера)?
- Сколько стоит каждый кластер (DBU + VM)?
Когда системные таблицы Unity Catalog (например, system.jobrunlogs) недоступны, стандартный подход на основе SQL не работает. REST API становится надежным решением.
Высокоуровневый подход, используемый в блокноте
- Список кластеров через /api/2.0/clusters/list.
- Оценка времени работы кластера с использованием временных меток внутри JSON кластера (поля created/start/terminated). (Это прагматичное решение, когда /clusters/events недоступен.)
- Получение последних запусков заданий с использованием /api/2.1/jobs/runs/list с временными фильтрами (или лимитом).
- Сопоставление запусков заданий с кластерами с использованием clusterinstance.clusterid (или других метаданных кластера).
- Расчет использования: % использования = totaljobruntime / totalclusteruptime.
- Оценка затрат с использованием простой формулы: затраты = runninghours × (DBU/hr × assumed DBU) + runninghours × nodes × VM $/hr.
Этот блокнот намеренно использует ограниченные запросы (последние N запусков, временное окно), чтобы работать быстро.
\ 1. Настройка и конфигурация
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Этот раздел инициализирует:
- URL рабочей области и токен для аутентификации
- Временной диапазон, для которого вы хотите проанализировать использование
- Предположения о затратах:
- Ставка DBU ($/час за DBU)
- Стоимость узла VM
- Приблизительное потребление DBU
В корпоративных настройках эти ставки могут быть получены динамически через ваши FinOps или APIs биллинга.
-
Функция-обертка API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Эта вспомогательная функция стандартизирует все REST API GET вызовы. \n Она:
-
Создает полный URL конечной точки
-
Обрабатывает 404 корректно (важно, когда кластеры или запуски истекли)
-
Возвращает распарсенный JSON
Почему это важно: Эта функция обеспечивает чистое взаимодействие с API без нарушения потока работы вашего блокнота, если какие-либо данные кластера отсутствуют.
\
-
Список всех активных кластеров
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Это извлекает все кластеры, доступные в вашей рабочей области. \n Это эквивалентно программному просмотру вашей вкладки "Compute". \n Ответ содержит:
-
ID кластеров
-
Имена
-
Количество узлов
-
Информацию о создателе
-
Время создания и завершения
Вариант использования: Помогает определить, какие кластеры потребляют ресурсы в выбранном окне.
4. Оценка времени работы кластера
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Мы рассчитываем общее время работы в часах для каждого кластера:
-
Использует временные метки создания и завершения
-
Обрабатывает текущие работающие кластеры (terminated_time отсутствует)
-
Нормализует до часов
Почему это важно: Это значение является знаменателем для использования — представляя общее время работы кластера в течение окна.
5. Получение последних запусков заданий
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Вместо извлечения всей истории заданий (что медленно), \n Эта функция извлекает последние 10 запусков заданий для быстрой диагностики.
В production вы можете фильтровать по:
- Конкретному job_id
- completed_only=true
- Окну дат (starttimefrom, starttimeto)
\
-
Расчет использования и затрат
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Это ядро логики:
-
Проходит по каждому кластеру
-
Рассчитывает общее время выполнения задания на кластер (используя API запусков заданий)
-
Выводит процент использования = (jobhours / clusterrunning_hours) × 100
-
Оценка затрат:
- Затраты DBU на основе ставки × DBU/час
- Затраты VM = nodecount × nodecost/час × running_hours
Почему это важно: \n Это дает единую картину эффективности и затрат — полезную для выявления кластеров с высокими затратами, но низким использованием.
7. Оркестрация конвейера
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Этот финальный блок:
-
Извлекает данные
-
Выполняет расчет затрат
-
Отображает отсортированный Data Frame
На практике этот Data Frame может быть:
-
Экспортирован в Excel или Delta Table
-
Отправлен на панели Power BI
-
Интегрирован в конвейеры автоматизации FinOps
\
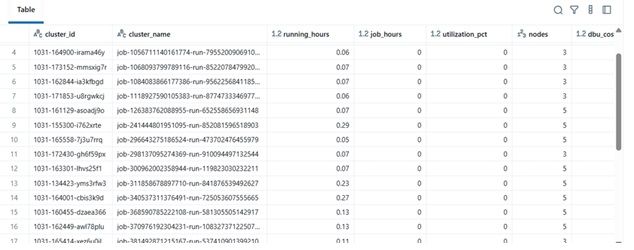
Пример результатов
| clustername | runninghours | jobhours | utilizationpct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | 142.8$ | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | 18.4$ | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | 260.4$ |
\ 
\ \
-
Реальная выгода
Внедрив этот анализатор:
-
Инженерные команды могут отслеживать затраты на кластеры даже без доступа к аудиту.
-
Менеджеры получают видимость недоиспользуемых кластеров.
-
DevOps может автоматически завершать кластеры с низким использованием.
-
Финансы могут проверять счета Databricks с помощью внутренних метрик.
В нашем проекте MSC мы использовали это как часть нашего стека наблюдаемости платформы данных — объединяя данные REST API, журналы заданий ADF и тренды затрат в единую панель.
\


Вам также может быть интересно

Пользователи Pi Network предупреждены: слухи об объединении сетей взрываются в сообществе

Dogecoin TD Sequential сигнализирует о продаже: впереди коррекция цены?




