

5 удивительных способов, которыми современный ИИ не может по-настоящему "мыслить"

Большие языковые модели (LLMs) демонстрируют взрывной рост возможностей, показывая замечательную производительность в задачах от понимания естественного языка до генерации кода. Мы взаимодействуем с ними ежедневно, и их беглость может быть поразительной, помещая нас прямо в зловещую долину искусственного интеллекта. Но равносильна ли эта сложная производительность подлинному мышлению, или это всего лишь высокотехнологичная иллюзия?
\ Растущий объем исследований предполагает, что за завесой компетентности скрывается набор глубоких и контринтуитивных ограничений. Эта статья исследует пять наиболее значительных неудач, которые обнажают пропасть между производительностью ИИ и истинным, человекоподобным пониманием.
Они не рассуждают усерднее; они просто разрушаются
Недавняя статья от Apple Research под названием "Иллюзия мышления" раскрывает критический недостаток даже в самых продвинутых "Больших моделях рассуждения" (LRMs), использующих такие техники, как цепочка мыслей. Исследование показывает, что эти модели на самом деле не рассуждают, а являются сложными симуляторами, которые сталкиваются с непреодолимой стеной, когда проблемы становятся достаточно сложными.
\ Исследователи использовали головоломку Ханойской башни для тестирования моделей, выявив три различных режима производительности в зависимости от сложности головоломки:
\
- Низкая сложность (3 диска): Стандартные, не рассуждающие модели работали так же хорошо или даже лучше, чем "мыслящие" модели LRM.
- Средняя сложность (6 дисков): LRM, генерирующие более длинную цепочку мыслей, показали явное преимущество.
- Высокая сложность (7+ дисков): Оба типа моделей испытали "полный крах", их точность упала до нуля.
\
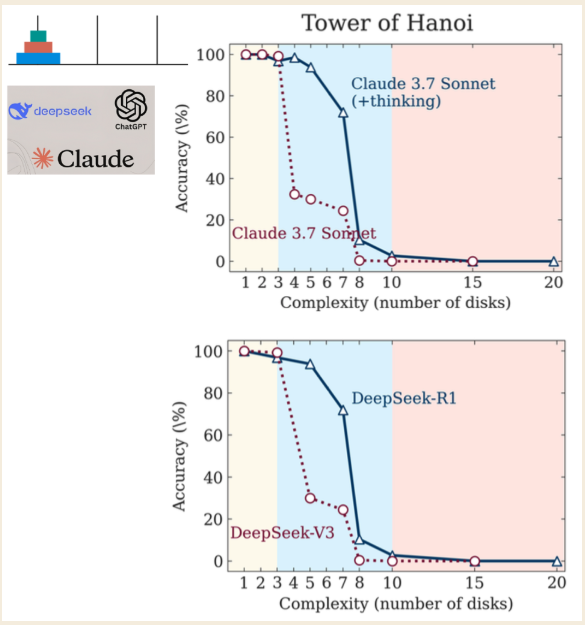
Наиболее контринтуитивным открытием было то, что модели "думают" меньше по мере усложнения проблем. Еще более обвинительно то, что они не могут правильно вычислять даже при явном предоставлении алгоритмов, необходимых для решения головоломки. Это указывает на фундаментальную неспособность применять правила под давлением, пустое подражание мысли, которое разрушается, когда это наиболее важно. (Исследователи отмечают, что хотя Anthropic, конкурирующая лаборатория ИИ, выдвинула возражения, они остаются незначительными придирками, а не фундаментальным опровержением результатов.)
\ Как выразились исследователи из Университета Аризоны, это поведение отражает суть иллюзии:
...предполагая, что LLM не являются принципиальными мыслителями, а скорее сложными симуляторами текста, похожего на рассуждение.
Их "Цепочка мыслей" часто является миражом
Цепочка мыслей (CoT) - это процесс, посредством которого LLM выписывает свои пошаговые "рассуждения" перед предоставлением окончательного ответа, функция, предназначенная для повышения точности и раскрытия внутренней логики. Однако недавнее исследование, анализирующее, как LLM справляются с базовой арифметикой, показывает, что этот процесс часто является "хрупким миражом".
\ Поразительно, существуют огромные несоответствия между шагами рассуждения в CoT и окончательным ответом, который предоставляет модель. В задачах, включающих простое сложение, было сделано шокирующее открытие: в более чем 60% образцов модель производила неправильные шаги рассуждения, которые каким-то образом, таинственно, приводили к правильному окончательному ответу.
\ Это эквивалентно тому, как если бы студент показывал бессмысленную работу на математическом тесте, но чудесным образом записывал правильное окончательное число. Вы бы не заключили, что они понимают материал; вы бы заподозрили, что они списали ответ. В ИИ это предполагает, что "рассуждение" часто является постфактум оправданием, а не подлинным мыслительным процессом. Это не ошибка, которая исправляется масштабированием; проблема усугубляется с более продвинутыми моделями, при этом частота этого противоречивого поведения увеличивается до 74% на GPT-4.
\ Если внутренний "мыслительный процесс" модели является миражом, что происходит, когда ее заставляют решать реальную, сложную проблему? Часто она погружается в безумие.
Они попадают в ловушку циклов "Погружения в безумие"
При использовании LLM для сложных задач, таких как отладка кода, может возникнуть опасный паттерн: "погружение в безумие" или "цикл галлюцинаций". Это цикл обратной связи, где LLM, пытаясь исправить ошибку программирования, попадает в нетерминирующий, иррациональный цикл. Она предлагает правдоподобно выглядящее исправление, которое не работает, и когда ее просят о другом решении, часто повторно вводит исходную ошибку, заманивая пользователя в бесплодный цикл.
\ Исследование, в котором программистам было поручено отлаживать код, выявило сенсационную тенденцию для рабочих процессов с помощью ИИ. Результаты были ясны: программисты без помощи ИИ решили больше задач правильно и меньше задач неправильно, чем группа, использовавшая LLM для помощи.
\ Осознайте это: в сложной задаче отладки наличие современного ИИ-помощника было не просто бесполезным — оно было активно вредным, приводя к худшим результатам, чем отсутствие ИИ вообще. Участники, использующие ИИ, часто застревали в этих бесплодных циклах, тратя время на концептуально необоснованные исправления. Исследователи также выявили проблему "шумного решения", где правильное исправление скрыто среди множества нерелевантных предложений, идеальный рецепт для человеческого разочарования. Эта ошибочная "помощь" подчеркивает, как впечатляющий внешний вид ИИ может скрывать глубоко ненадежное ядро, особенно когда ставки высоки.
Их впечатляющие эталоны построены на фундаменте недостатков
Когда компании ИИ выпускают новые модели, они указывают на впечатляющие эталонные показатели, чтобы доказать свое превосходство. Однако более пристальный взгляд может выявить гораздо менее лестную картину.
\ SWE-bench (Эталон программной инженерии), используемый для измерения способности LLM исправлять реальные проблемы программного обеспечения из GitHub, является ярким примером для изучения. Независимое исследование из Йоркского университета обнаружило критические недостатки, которые сильно завышали воспринимаемые возможности моделей:
\
- Утечка решений ("Мошенничество"): В 32,67% успешных патчей правильное решение уже было предоставлено в самом отчете о проблеме.
- Слабые тесты: В 31,08% случаев, когда модель "прошла", проверочные тесты были слишком слабыми, чтобы фактически подтвердить правильность исправления.
\ Когда эти ошибочные случаи были отфильтрованы, реальная производительность топовой модели (SWE-Agent + GPT-4) резко упала. Ее показатель разрешения снизился с рекламируемых 12,47% до всего лишь 3,97%. Кроме того, более 94% проблем в эталоне были созданы до даты отсечения знаний LLM, что вызывает серьезные вопросы об утечке данных.
\ Это раскрывает тревожную реальность: эталоны часто являются маркетинговыми инструментами, представляющими наилучший сценарий, выращенный в лаборатории, который рушится при реальной проверке. Разрыв между рекламируемой мощностью и проверенной производительностью не трещина; это каньон.
Они осваивают правила, но фундаментально не понимают
Даже если бы все вышеуказанные технические неудачи были исправлены, остается более глубокий, более философский барьер. LLM не хватает основных компонентов человеческого интеллекта. В то время как философы обсуждают сознание и интенциональность, многие аргументы предполагают, что рациональность, то есть наша способность понимать универсальные концепции и логически рассуждать, является ключевым аспектом, уникальным для людей и отсутствующим в ИИ.
\ Эта идея подкрепляется физиком Роджером Пенроузом, который использует теорему о неполноте Гёделя, чтобы утверждать, что человеческое математическое понимание превосходит любой фиксированный набор алгоритмических правил. Представьте любой алгоритм как конечный свод правил. Теорема Гёделя показывает, что человек-математик всегда может посмотреть на свод правил извне и понять истины, которые сам свод правил не может доказать.
\ Наши умы не просто следуют правилам в книге; мы можем прочитать всю книгу и понять ее ограничения. Эта способность к проникновению, это "невычислимое" понимание, и есть то, что отделяет человеческое познание даже от самого продвинутого ИИ.
\ LLM являются мастерами манипулирования символами на основе алгоритмов и статистических паттернов. Однако они не обладают осознанием, необходимым для подлинного понимания. Как заключает один мощный аргумент:
Трюк фокусника
Хотя LLM, несомненно, являются мощными инструментами, которые могут симулировать интеллектуальное поведение с жуткой точностью, накапливающиеся доказательства показывают, что они больше похожи на сложные симуляторы, чем на подлинных мыслителей. Их производительность — это грандиозная иллюзия, ослепительное зрелище компетентности, которое разваливается под давлением, противоречит собственной логике и опирается на ошибочные метрики. Это подобно трюку фокусника (казалось бы, невозможному), но в конечном итоге иллюзии, построенной на умных техниках, а не на настоящей магии. По мере того, как мы продолжаем интегрировать эти системы в наш мир, мы должны оставаться критичными и задавать существенный вопрос:
\ Если эти ИИ-машины ломаются на более сложных проблемах, даже когда вы даете им алгоритмы и правила, действительно ли они мыслят или просто очень хорошо притворяются?
Подкаст:
\
- Apple: ЗДЕСЬ
- Spotify: ЗДЕСЬ


Вам также может быть интересно

Bitcoin Depot (BTCD) рухнул: крупнейшая сеть криптовалютных банкоматов Америки подаёт заявление о банкротстве по главе 11

Бывший технический директор Ripple Шварц отправил XRP на сенатскую кампанию Джона Дитона




