

Обучение ИИ видеть и говорить: внутри подхода OW‑VISCap
Таблица ссылок
Резюме и 1. Введение
-
Связанные работы
2.1 Сегментация видеоэкземпляров в открытом мире
2.2 Плотное описание видеообъектов и 2.3 Контрастные потери для запросов объектов
2.4 Обобщенное понимание видео и 2.5 Сегментация видеоэкземпляров в закрытом мире
-
Подход
3.1 Обзор
3.2 Запросы объектов открытого мира
3.3 Головка подписи
3.4 Межзапросная контрастная потеря и 3.5 Обучение
-
Эксперименты и 4.1 Наборы данных и метрики оценки
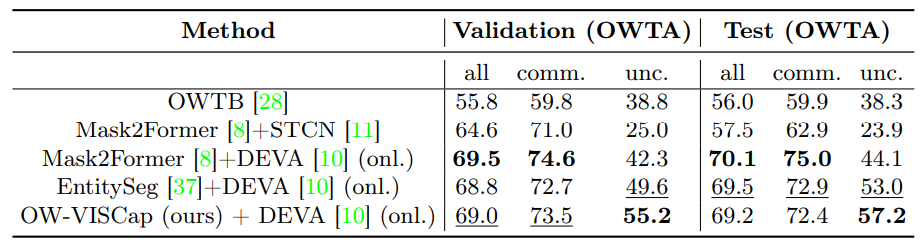
4.2 Основные результаты
4.3 Исследования абляции и 4.4 Качественные результаты
-
Заключение, благодарности и ссылки
\ Дополнительные материалы
A. Дополнительный анализ
B. Детали реализации
C. Ограничения
3 Подход
Учитывая видео, наша цель - совместно обнаруживать, сегментировать и подписывать экземпляры объектов, присутствующие в видео. Важно отметить, что категории экземпляров объектов могут не входить в обучающий набор (например, парашюты, показанные на рис. 3 (верхний ряд)), что помещает нашу цель в условия открытого мира. Для достижения этой цели данное видео сначала разбивается на короткие клипы, каждый из которых состоит из T кадров. Каждый клип обрабатывается с использованием нашего подхода OW-VISCap. Мы обсуждаем объединение результатов каждого клипа в разделе 4.
\ Мы предоставляем обзор OW-VISCap для обработки каждого клипа в разделе 3.1. Затем мы обсуждаем наши вклады: (a) введение запросов объектов открытого мира в разделе 3.2, (b) использование маскированного внимания для объектно-ориентированного подписывания в разделе 3.3 и (c) использование межзапросной контрастной потери для обеспечения того, чтобы запросы объектов отличались друг от друга в разделе 3.4. В разделе 3.5 мы обсуждаем конечную цель обучения.
3.1 Обзор
\ Запросы объектов как открытого, так и закрытого мира обрабатываются нашей специально разработанной головкой подписи, которая дает объектно-ориентированную подпись, головкой классификации, которая дает метку категории, и головкой обнаружения, которая дает либо маску сегментации, либо ограничивающую рамку.
\ 
\ Мы вводим межзапросную контрастную потерю, чтобы гарантировать, что запросы объектов поощряются отличаться друг от друга. Мы предоставляем подробности в разделе 3.4. Для объектов закрытого мира эта потеря помогает устранить сильно перекрывающиеся ложные срабатывания. Для объектов открытого мира она помогает в обнаружении новых объектов.
\ Наконец, мы предоставляем полную цель обучения в разделе 3.5.
\
3.2 Запросы объектов открытого мира
\ 
\ 
\ Сначала мы сопоставляем объекты истинных данных с предсказаниями открытого мира, минимизируя стоимость сопоставления с использованием венгерского алгоритма [34]. Оптимальное сопоставление затем используется для расчета окончательной потери открытого мира.
\ 
\
3.3 Головка подписи
\ 
\
3.4 Межзапросная контрастная потеря
\ 
\
3.5 Обучение
Наша общая потеря обучения составляет
\ 
\ ![Таблица 2: Результаты плотного описания видеообъектов на наборе данных VidSTG [57]. Off. указывает на офлайн-методы, а onl. относится к онлайн-методам.](https://cdn.hackernoon.com/images/null-0v3336a.png)
\
:::info Авторы:
(1) Anwesa Choudhuri, Университет Иллинойса в Урбана-Шампейн (anwesac2@illinois.edu);
(2) Girish Chowdhary, Университет Иллинойса в Урбана-Шампейн (girishc@illinois.edu);
(3) Alexander G. Schwing, Университет Иллинойса в Урбана-Шампейн (aschwing@illinois.edu).
:::
:::info Эта статья доступна на arxiv по лицензии CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Вам также может быть интересно

SEC готовится представить структуру для торговли токенами акций на этой неделе

Гонка за место в Верховном суде колеблющегося штата столкнулась с bizarre поворотом в вопросах этики в последний момент




