

Вот почему исследователи ИИ говорят о разреженном спектральном обучении
Таблица ссылок
Резюме и 1. Введение
-
Связанные работы
-
Низкоранговая адаптация
3.1 LoRA и 3.2 Ограничения LoRA
3.3 ReLoRA*
-
Разреженное спектральное обучение
4.1 Предварительные сведения и 4.2 Градиентное обновление U, VT с Σ
4.3 Почему важна инициализация SVD
4.4 SST балансирует эксплуатацию и исследование
4.5 Эффективная по памяти реализация для SST и 4.6 Разреженность SST
-
Эксперименты
5.1 Машинный перевод
5.2 Генерация естественного языка
5.3 Гиперболические графовые нейронные сети
-
Заключение и обсуждение
-
Более широкое влияние и ссылки
Дополнительная информация
A. Алгоритм разреженного спектрального обучения
B. Доказательство градиента разреженного спектрального слоя
C. Доказательство разложения градиента веса
D. Доказательство преимущества улучшенного градиента над стандартным градиентом
E. Доказательство нулевого искажения с инициализацией SVD
F. Детали эксперимента
G. Отсечение сингулярных значений
H. Оценка SST и GaLore: дополнительные подходы к эффективности памяти
I. Исследование абляции
A Алгоритм разреженного спектрального обучения
B Доказательство градиента разреженного спектрального слоя
Мы можем выразить дифференциал W как сумму дифференциалов:
\ \ 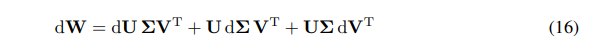
\ \ Мы имеем правило цепи для градиента W:
\ \ 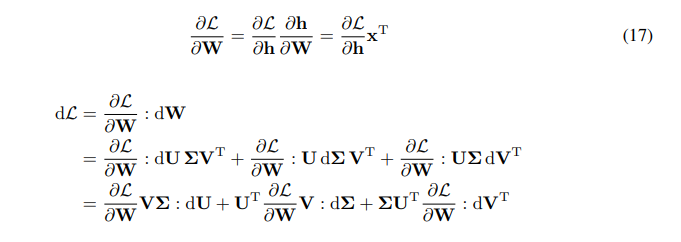
\ \ \ 
\
C Доказательство разложения градиента веса
\ 
\
D Доказательство преимущества улучшенного градиента над стандартным градиентом
\ 
\ \ \ 
\ \ \ 
\ \ Поскольку важно только направление обновления, масштаб обновления можно регулировать, изменяя скорость обучения. Мы измеряем сходство, используя норму Фробениуса разностей между обновлениями SST и трехкратным полноранговым обновлением.
\ \ 
\
E Доказательство нулевого искажения с инициализацией SVD
\ 
F Детали эксперимента
F.1 Детали реализации для SST
\ 
\ \ \ 
\
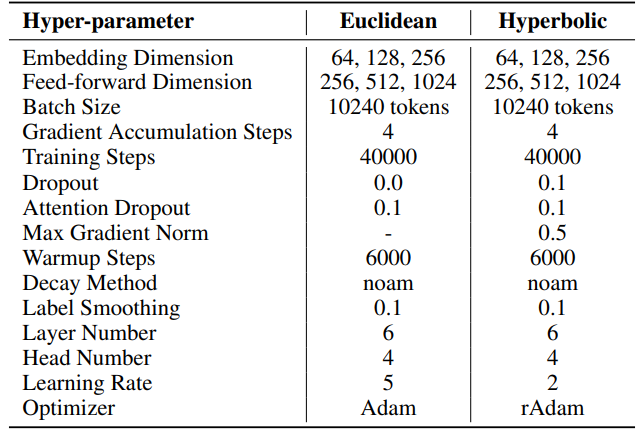
F.2 Гиперпараметры машинного перевода
IWSLT'14. Гиперпараметры можно найти в Таблице 6. Мы используем ту же кодовую базу и гиперпараметры, что и в HyboNet [12], которая основана на OpenNMT-py [54]. Для оценки используется финальная контрольная точка модели. Для оптимизации процесса оценки применяется лучевой поиск с размером луча 2. Эксперименты проводились на одном GPU A100.
\ Для SST количество шагов на итерацию (T3) установлено на 200. Каждая итерация начинается с фазы разогрева, длящейся 20 шагов. Количество итераций за раунд (T2) определяется по формуле T2 = d/r, где d представляет размерность вложения, а r обозначает ранг, используемый в SST.
\ \ 
\ \ \ 
\ \ Для SST количество шагов на итерацию (T3) установлено на 200 для Multi30K и 400 для IWSLT'17. Каждая итерация начинается с фазы разогрева, длящейся 20 шагов. Количество итераций за раунд (T2) определяется по формуле T2 = d/r, где d представляет размерность вложения, а r обозначает ранг, используемый в SST
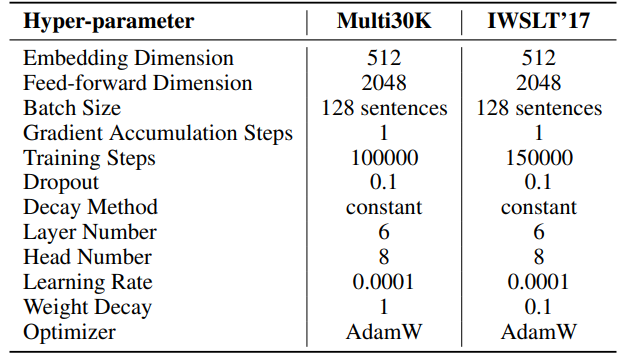
F.3 Гиперпараметры генерации естественного языка
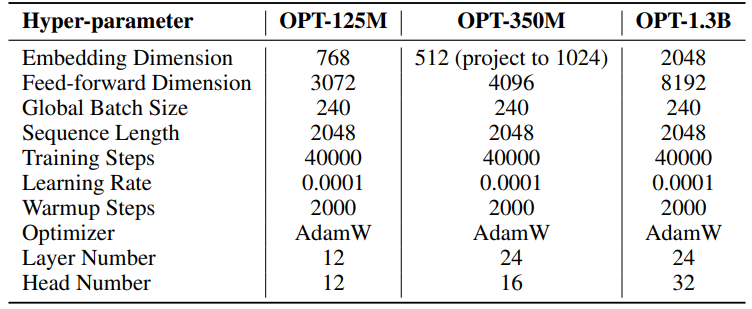
Гиперпараметры для наших экспериментов подробно описаны в Таблице 8. Мы используем линейный разогрев в течение 2000 шагов, за которым следует стабильная скорость обучения без затухания. Более высокая скорость обучения (0.001) используется только для низкоранговых параметров (U, VT и Σ для SST, B и A для LoRA и ReLoRA*. Общее количество токенов обучения для каждого эксперимента составляет 19,7 млрд, примерно 2 эпохи OpenWebText. Распределенное обучение осуществляется с использованием библиотеки Accelerate [55] на четырех GPU A100 на сервере Linux.
\ Для SST количество шагов на итерацию (T3) установлено на 200. Каждая итерация начинается с фазы разогрева, длящейся 20 шагов. Количество итераций за раунд (T2) определяется по формуле T2 = d/r, где d представляет размерность вложения, а r обозначает ранг, используемый в SST.
\ \ 
\ \ \ 
\
F.4 Гиперпараметры гиперболических графовых нейронных сетей
Мы используем HyboNet [12] как полноранговую модель с теми же гиперпараметрами, что и в HyboNet. Эксперименты проводились на одном GPU A100.
\ Для SST количество шагов на итерацию (T3) установлено на 100. Каждая итерация начинается с фазы разогрева, длящейся 100 шагов. Количество итераций за раунд (T2) определяется по формуле T2 = d/r, где d представляет размерность вложения, а r обозначает ранг, используемый в SST.
\ Мы устанавливаем коэффициент отсева 0,5 для методов LoRA и SST во время задачи классификации узлов на наборе данных Cora. Это единственное отклонение от конфигурации HyboNet.
\ \ \
:::info Авторы:
(1) Цзялинь Чжао, Центр интеллекта сложных сетей (CCNI), Лаборатория мозга и интеллекта Университета Цинхуа (THBI) и кафедра компьютерных наук;
(2) Интао Чжан, Центр интеллекта сложных сетей (CCNI), Лаборатория мозга и интеллекта Университета Цинхуа (THBI) и кафедра компьютерных наук;
(3) Синхан Ли, кафедра компьютерных наук;
(4) Хуапин Лю, кафедра компьютерных наук;
(5) Карло Витторио Канистраци, Центр интеллекта сложных сетей (CCNI), Лаборатория мозга и интеллекта Университета Цинхуа (THBI), кафедра компьютерных наук и кафедра биомедицинской инженерии Университета Цинхуа, Пекин, Китай.
:::
:::info Эта статья доступна на arxiv по лицензии CC by 4.0 Deed (Attribution 4.0 International).
:::
\

Вам также может быть интересно

Nexira запускается сегодня: получите свой аирдроп $NEXI раньше всех и наблюдайте взрывной рост цен!

Латинская Америка обгоняет США по числу владельцев криптовалют
