

Как Toto переосмысливает мультиголовое внимание для многомерного прогнозирования

Таблица ссылок
- Предыстория
- Постановка проблемы
- Архитектура модели
- Обучающие данные
- Результаты
- Выводы
- Заявление о влиянии
- Направления будущего развития
- Вклады
- Благодарности и ссылки
Приложение
3 Архитектура модели
Toto - это модель прогнозирования, основанная только на декодере. Эта модель использует многие из последних методов из литературы и представляет новый метод адаптации многоголового внимания к многомерным временным рядам (Рис. 1).
\ 3.1 Дизайн трансформера
\ Модели трансформеров для прогнозирования временных рядов использовали различные архитектуры: кодер-декодер [12, 13, 21], только кодер [14, 15, 17] и только декодер [19, 23]. Для Toto мы используем архитектуру, основанную только на декодере. Архитектуры декодеров показали хорошую масштабируемость [25, 26] и позволяют использовать произвольные горизонты прогнозирования. Задача причинного предсказания следующего патча также упрощает процесс предварительного обучения.
\ Мы используем методы из некоторых новейших архитектур больших языковых моделей (LLM), включая пренормализацию [27], RMSNorm [28] и SwiGLU прямонаправленные слои [29].
\ 3.2 Входное встраивание
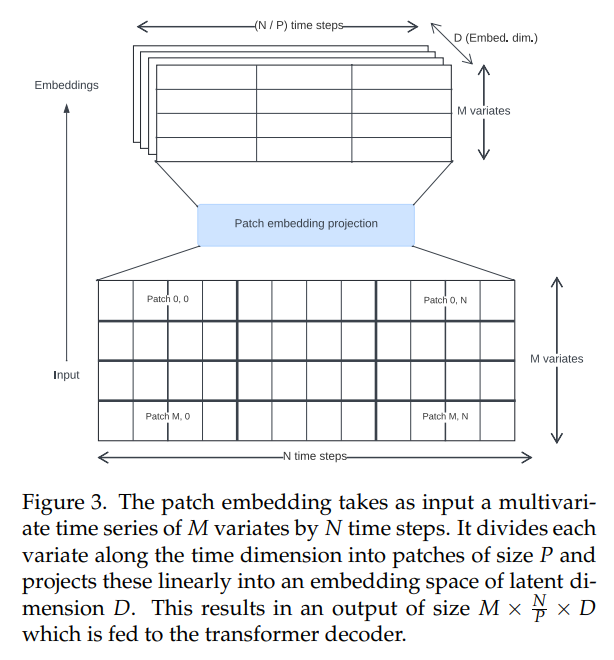
\ Трансформеры временных рядов в литературе использовали различные подходы для создания входных встраиваний. Мы используем неперекрывающиеся проекции патчей (Рис. 3), впервые представленные для Vision Transformers [30, 31] и популяризированные в контексте временных рядов PatchTST [14]. Toto была обучена с использованием фиксированного размера патча 32.
\ 
\ 3.3 Механизм внимания
\ Метрики наблюдаемости часто представляют собой многомерные временные ряды высокой кардинальности. Поэтому идеальная модель должна изначально обрабатывать многомерное прогнозирование. Она должна уметь анализировать отношения как во временном измерении (то, что мы называем взаимодействиями "по времени"), так и в канальном измерении (то, что мы называем взаимодействиями "по пространству", следуя соглашению на платформе Datadog об описании различных групп или наборов тегов метрики как "пространственного" измерения).
\ Чтобы моделировать взаимодействия как в пространстве, так и во времени, нам нужно адаптировать традиционную архитектуру многоголового внимания [11] с одного на два измерения. В литературе было предложено несколько подходов для этого, включая:
\ • Предположение о независимости каналов и вычисление внимания только во временном измерении [14]. Это эффективно, но отбрасывает всю информацию о пространственных взаимодействиях.
\ • Вычисление внимания только в пространственном измерении и использование прямонаправленной сети во временном измерении [17, 18].
\ • Конкатенация вариат вдоль временного измерения и вычисление полного перекрестного внимания между каждым пространственно-временным местоположением [15]. Это может охватить все возможные пространственные и временные взаимодействия, но требует больших вычислительных затрат.
\ • Вычисление "факторизованного внимания", где каждый блок трансформера содержит отдельные вычисления внимания для пространства и времени [16, 32, 33]. Это позволяет смешивать как пространство, так и время, и более эффективно, чем полное перекрестное внимание. Однако это удваивает эффективную глубину сети.
\ Чтобы разработать наш механизм внимания, мы следуем интуиции, что для многих временных рядов временные отношения более важны или предсказательны, чем пространственные отношения. В качестве доказательства мы наблюдаем, что даже модели, которые полностью игнорируют пространственные отношения (такие как PatchTST [14] и TimesFM [19]), все равно могут достичь конкурентоспособной производительности на многомерных наборах данных. Однако другие исследования (например, Moirai [15]) показали через абляции, что есть некоторая явная польза от включения пространственных отношений.
\ Поэтому мы предлагаем новый вариант факторизованного внимания, который мы называем "Пропорциональное факторизованное пространственно-временное внимание". Мы используем смесь чередующихся блоков внимания по пространству и по времени. В качестве настраиваемого гиперпараметра мы можем изменять соотношение блоков по времени к блокам по пространству, что позволяет нам выделять больше или меньше вычислительных ресурсов для каждого типа внимания. Для нашей базовой модели мы выбрали конфигурацию с одним блоком внимания по пространству на каждые два блока по времени.
\ В блоках внимания по времени мы используем причинное маскирование и вращательные позиционные встраивания [34] с XPOS [35] для авторегрессивного моделирования зависимых от времени признаков. В блоках по пространству, напротив, мы используем полное двунаправленное внимание для сохранения инвариантности перестановок ковариат, с блочно-диагональной ID-маской, чтобы гарантировать, что только связанные вариаты обращают внимание друг на друга. Это маскирование позволяет нам упаковывать несколько независимых многомерных временных рядов в одну партию, чтобы повысить эффективность обучения и уменьшить количество заполнения.
\ 3.4 Вероятностная голова предсказания
\ Чтобы быть полезной для приложений прогнозирования, модель должна производить вероятностные предсказания. Общая практика в моделях временных рядов - использовать выходной слой, где модель регрессирует параметры вероятностного распределения. Это позволяет вычислять интервалы предсказаний с использованием выборки Монте-Карло [7].
\ Распространенными вариантами для выходного слоя являются Нормальное распределение [7] и Стьюдента-T [23, 36], которые могут повысить устойчивость к выбросам. Moirai [15] позволяет использовать более гибкие остаточные распределения, предлагая новую смешанную модель, включающую взвешенную комбинацию выходов Гауссова, Стьюдента-T, Лог-нормального и отрицательного биномиального распределений.
\ Однако реальные временные ряды часто имеют сложные распределения, которые трудно подогнать, с выбросами, тяжелыми хвостами, экстремальной асимметрией и мультимодальностью. Чтобы учесть эти сценарии, мы вводим еще более гибкую выходную вероятность. Для этого мы используем метод, основанный на моделях смеси Гаусса (GMMs), которые могут аппроксимировать любую функцию плотности ([37]). Чтобы избежать нестабильности обучения при наличии выбросов, мы используем модель смеси Стьюдента-T (SMM), надежное обобщение GMMs [38], которое ранее показало перспективы для моделирования финансовых временных рядов с тяжелыми хвостами [39, 40]. Модель предсказывает k распределений Стьюдента-T (где k - гиперпараметр) для каждого временного шага, а также обученное взвешивание.
\ 
\ Когда мы выполняем вывод, мы берем выборки из смешанного распределения в каждый момент времени, затем подаем каждую выборку обратно в декодер для следующего предсказания. Это позволяет нам получать интервалы предсказаний на любом квантиле, ограниченные только количеством выборок; для более точных хвостов мы можем выбрать тратить больше вычислений на выборку (Рис. 2).
\ 3.5 Масштабирование входа/выхода
\ Как и в других моделях временных рядов, мы выполняем нормализацию экземпляров на входных данных перед их прохождением через встраивание патчей, чтобы модель лучше обобщалась на входы разных масштабов [41]. Мы масштабируем входы, чтобы они имели нулевое среднее и единичное стандартное отклонение. Выходные предсказания затем масштабируются обратно к исходным единицам.
\ 3.6 Цель обучения
\ Как модель, основанная только на декодере, Toto предварительно обучается на задаче предсказания следующего патча. Мы минимизируем отрицательное логарифмическое правдоподобие следующего предсказанного патча относительно выходного распределения модели. Мы обучаем модель с использованием оптимизатора AdamW [42].
\ 3.7 Гиперпараметры
\ Гиперпараметры, используемые для Toto, подробно описаны в Таблице A.1, с общим количеством параметров 103 миллиона.
\
:::info Авторы:
(1) Бен Коэн (ben.cohen@datadoghq.com);
(2) Эмаад Хваджа (emaad@datadoghq.com);
(3) Кан Ван (kan.wang@datadoghq.com);
(4) Чарльз Массон (charles.masson@datadoghq.com);
(5) Элиз Раме (elise.rame@datadoghq.com);
(6) Юссеф Дубли (youssef.doubli@datadoghq.com);
(7) Отман Абу-Амаль (othmane@datadoghq.com).
:::
:::info Эта статья доступна на arxiv под лицензией CC BY 4.0.
:::
\


Вам также может быть интересно

Республиканцы Теннесси ликвидируют последний округ с большинством чернокожего населения
Заявка T. Rowe Price на ETF добавляет экспозицию ADA, пока покупатели, делающие прогнозы по цене Cardano, следят за кейсом AlphaPepe на $1




