

The Price of BigQuery and the True Cost of Being Data-Driven

Intro
Hi everyone! My name is Max — I lead the Data Platform and ML at Tabby.
My teams and I would like to share the experience we’ve accumulated over the past few years, and this article is the first in a series about building a modern Data Platform from scratch.
I’m confident that our experience combining Google Cloud Platform services, open-source industry-standard solutions, and our own technological approaches will find an audience and be useful.
\
Data Warehouse Concept
Why do various companies even create a corporate data warehouse, and can we do without it?
The development and evolution of a corporate data warehouse are essential if you really want your company to grow, and be Data-Driven or Data-Informed, so that the management receives timely analytics and reporting for decision-making or goal-setting. It’s more a necessity than just a fashionable accessory.
\ Let’s briefly outline the main areas of application for DWH in my opinion:
-
Daily ad-hoc analytics
-
Regular reporting and monitoring of business metrics
-
Data Mining, Statistical Analysis, Machine Learning
-
Accumulation of historical business knowledge
\
What were the main problems we wanted to solve when starting the development of our own DWH:
- The inconvenience and unsuitability of the service data storage in PostgreSQL for analytics (difficulty in horizontal scaling, inability to refer to data on different instances in a single SQL query, additional load on the database itself);
- From the first point follows that there is the inconvenience of integration with BI systems. It is worth clarifying that the difficulty is not in the technical connection of PostgreSQL, for example, to Tableau or similar BI systems, but in optimally assembling the necessary data mart and visualising it on charts;
- The absence of a logic for data separation as a resource among different user groups, in other words, not every developer needs to have access to sensitive financial data;
- Lack of tools for creating analytical data marts of any complexity and other data transformations;
- Synchronisation of data between the authoritative repository (service database PostgreSQL) and the analytical repository DWH while maintaining consistency and meeting data quality requirements, and synchronisation with external data sources.
\
Design & Architecture
The main idea that we established in the manifesto before even starting to work on the design and development had the following definition:
\
\ Let’s move on to discussing the architecture and technical stack of the DWH.
Why did we choose Google Cloud Platform as the primary platform for implementing our ideas? This is perhaps the simplest question we had to answer. GCP was chosen before us, and all the technical components of Tabby’s business were already implemented on this platform, so there is no point in creating problems for ourselves in terms of expertise and support.
At the very beginning of this large journey, it was necessary to answer the question of what to choose as the basis of the technology stack. We decided to go with a cloud technology stack, specifically Google Cloud Platform.
\ Our choice was based on several main aspects:
- The company was already using Google Cloud Platform, which meant there was already internal expertise;
- The ease of integration between different technological blocks that use the same platform and a similar set of tools;
- A fairly large part of infrastructure problems is solved by the platform itself, allowing us to concentrate specifically on development and implementation of user functionality.
\ I suggest we take a look at the design diagram of our repository’s architecture right now, and then talk about the details.
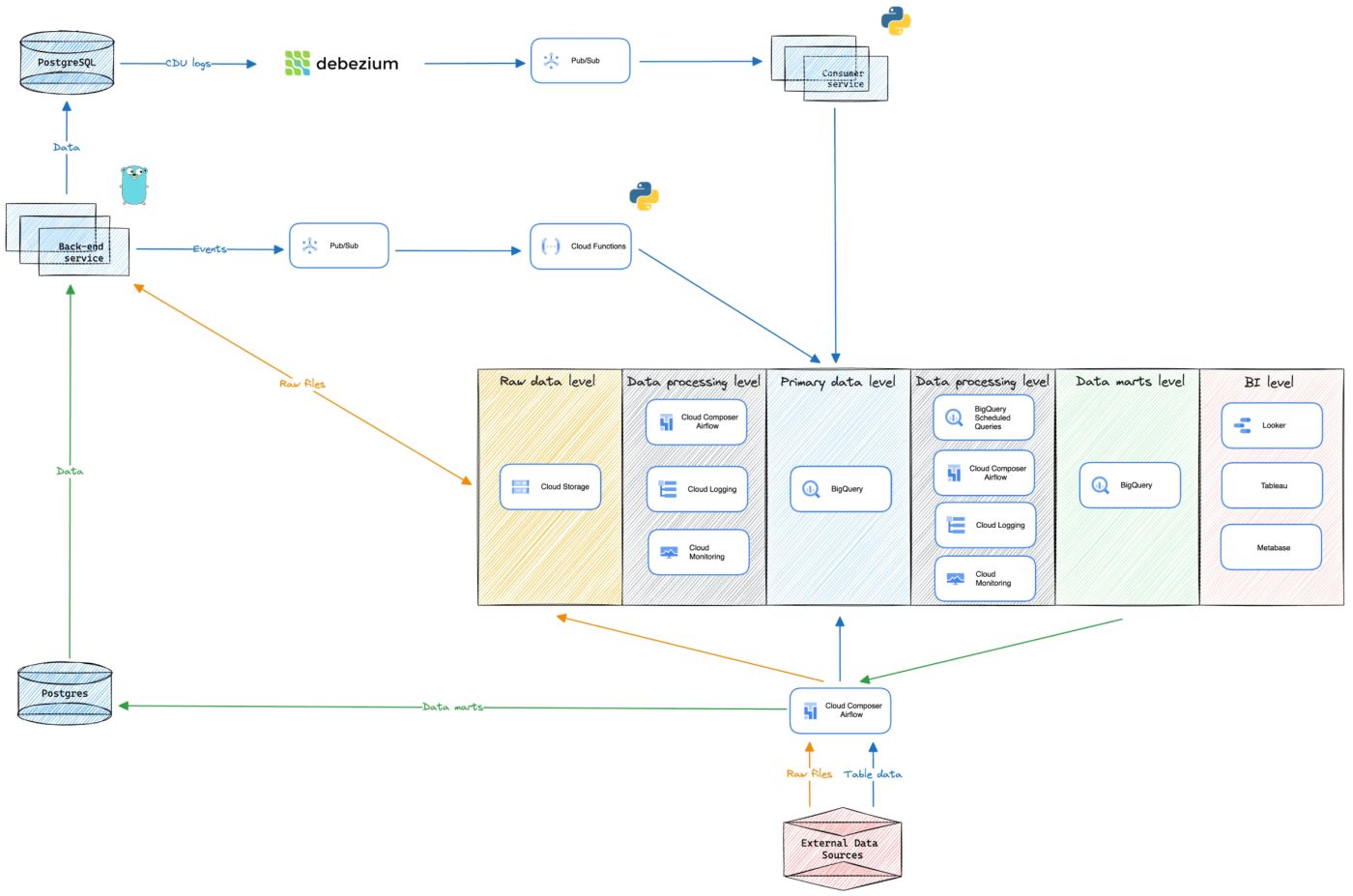
\
Data storing, processing & manipulations
Analytical database
As the heart of our DWH, we chose Google BigQuery, a columnar database designed for storing and processing large volumes of data.
\ What Google BigQuery offers as one of the GCP services:
- Horizontal scalability to meet needs
- Settings for the logic of creating backups
- Settings for the logic of resource and data separation among user groups
- Ensuring basic data security through encryption
- Logging and monitoring
\ This was exactly what we needed: a scalable database that allows to use a single SQL script to combine data from different business directions and build a data mart that answers the posed questions. Also, it allows quite flexible configuration of data storage mechanics and data usage with the possibility to restore corrupted or lost data at any moment.
Of course, it has its downsides, and the biggest is the cost. If you don’t take care of optimizations at the data storage level and teach Google BigQuery users the best practices for writing SQL scripts, the bill for using Google BigQuery at the end of the month can be very surprising and upsetting. How we solved this problem at the level of data storage and user experience will be discussed in the following articles.
\
Data levels for DWH
\ 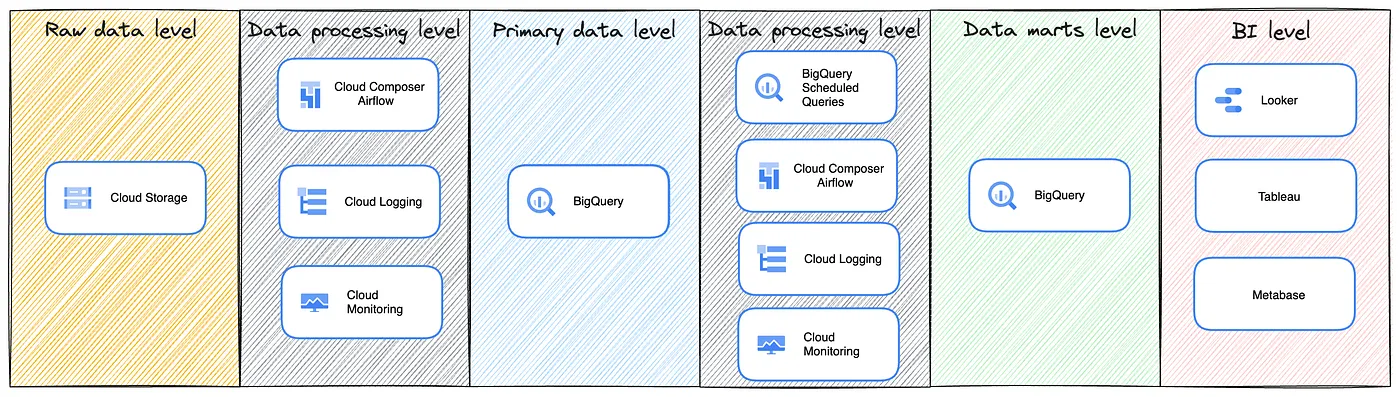
\ We have identified 4 main levels of data storage and representation:
- Raw data level — Cloud Storage file repository, designed for storing and exchanging non-tabular data such as .csv / .parquet files or images. Additionally, on this level, we store extra backup copies of Google BigQuery data;
- Primary data level — The logical level of data storage in Google BigQuery. At this level, data synchronization occurs from the authoritative PostgreSQL repository, as well as direct event uploads from business logic implementing services and synchronisation with external data sources. Users do not have the rights to create any entities or perform manual data modification and insertion operations into tables at this level;
- Data marts level — The logical processing of data stored at the Primary data level and the storage of data marts. BI systems are connected to this level, where analysts can visualise the resulting data marts. At this level, all users have the rights to create tables, views, materialised views, and other entities;
- Data processing level — The combination of all the tools that allow data delivery to all previous levels and manipulations on them (Cloud Composer / Airflow, Cloud Functions, Cloud PubSub, BigQuery Scheduled Queries);
- BI level — This is the level of data visualisation and reporting based on data, with the data marts level being the source.
\ The logic of data and data mart storage at the Primary data level and Data marts level is oriented towards the company’s product structure. For the main users — analysts, it’s not important how these data are originally stored in PostgreSQL, they are much more interested in which business direction or product they relate to. The combinatorics are very simple: one business direction, one pair of datasets at the Primary data level, and Data marts level.
Additionally, the business-oriented logic allows us to provide access only to the data that an analyst truly needs to access to perform their work. For this, it is necessary to create user groups in Google Cloud Platform and divide access at the level of dataset tables.
\ 
\
Synchronisation
It may seem that everything worked out easily, and on the first try for us. This is not the case, and now we will move on to a really big problem, which has required extensive custom development.
We needed a data synchronisation system from PostgreSQL to Google BigQuery, with a synchronisation frequency close to real-time and the ability for customisation in case of changing requirements.
We started solving this problem by searching for ready-made tools in Google Cloud Platform, and there indeed is one (actually, there are several), and we liked Google Datastream the most. It allows data to be delivered from point A to point B, but it has a limited set of sources: MySQL, Oracle, and we needed PostgreSQL, so we decided not to use it.
\
\ At the same time, we were exploring the SaaS solution market. The most promising solution was Fivetran, which allowed setting up data synchronisation from PostgreSQL to Google BigQuery. We could have used it, but considering that we expected high costs for using Google BigQuery when launching DWH, we did not want to pay a hefty sum for synchronisation and at the same time not have the ability to fully control and customise such a solution. I want to make sure we’re on the same page, so I’ll state explicitly, without synchronising data from PostgreSQL as the main authoritative system and primary data provider, there’s no point in DWH. Therefore, we must be sure that we can guarantee the stability of this block and will be able to quickly solve problems, rather than waiting for external developers to resolve the issue.
At the same time, we were exploring the SaaS solution market. The most promising solution was Fivetran, which allowed setting up data synchronisation from PostgreSQL to Google BigQuery. We could have used it, but considering that we expected high costs for using Google BigQuery when launching DWH, we did not want to pay a hefty sum for synchronisation and at the same time not have the ability to fully control and customise such a solution. I want to make sure we’re on the same page, so I’ll state explicitly, without synchronising data from PostgreSQL as the main authoritative system and primary data provider, there’s no point in DWH. Therefore, we must be sure that we can guarantee the stability of this block and will be able to quickly solve problems, rather than waiting for external developers to resolve the issue.
So, we rejected Google Datastream because it does not work with PostgreSQL, and we don’t want to pay for a SaaS without being able to look under the hood, so we’re left with developing it ourselves.
\ 
\ The primary technology for implementing the data synchronisation service between PostgreSQL and Google BigQuery is Debezium and the Google PubSub message broker:
- Debezium connects to the PostgreSQL log journal, reading them and sending to the PubSub message queue, operations CREATE, DELETE, UPDATE. Usually, Debezium is used with the Kafka message broker, but Google PubSub is Kafka in the world of GCP, with similar message-handling mechanics;
- A consumer connects to the message queue and transforms the logs into real changes in corresponding Google BigQuery tables.
As a result, we get a data synchronisation service close to real-time.
\
\
Data manipulations, ETL / ELT / EL
Alright, we’ve figured out how to store data and how to synchronise with the main authoritative system, and we’ve even figured out how to restrict different user groups’ access to different data. Now, what remains is to understand how to extract useful business knowledge from the data using transformations.
\ 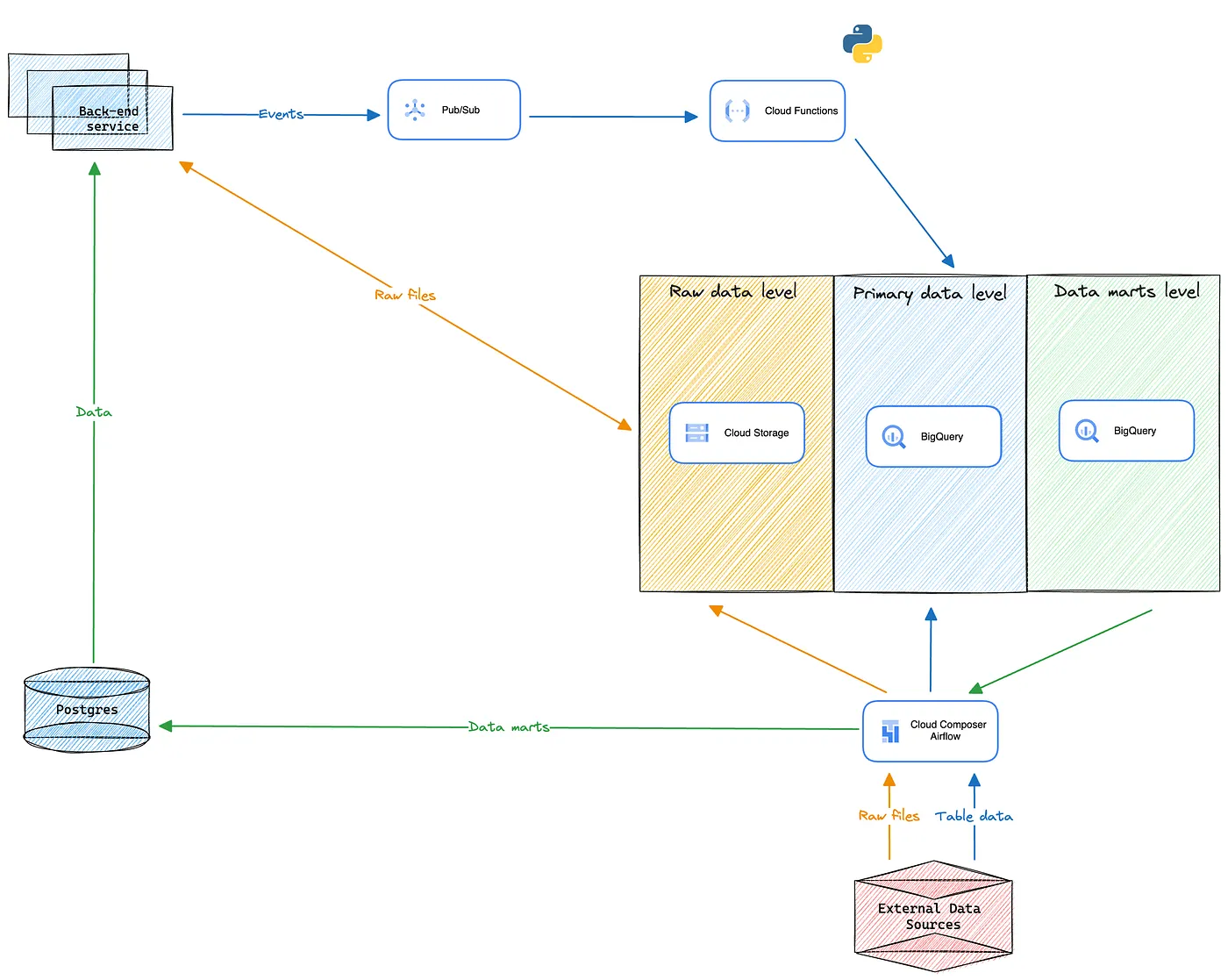
\ As tools for creating data marts, we use Google BigQuery Scheduled Queries and Google Composer / Airflow:
-
If a data mart can be created using only SQL, and its creation logic is not complex, we use Scheduled Queries. Users write the SQL script themselves and deploy it through GitLab with settings for execution schedules and other parameters, for example, the data writing method, either rewrite or append. The result of such queries are materialised views, which can then be used for BI systems or for building more complex data marts;
-
If it’s difficult to create a data mart using only SQL, and its creation logic is somewhat complex, or if the result needs to be not just saved at the Data marts level, but pushed into production for backend services to expand their capabilities and bypass the limitations of the microservice architecture, we use AirFlow. The development of such pipelines is primarily handled by the Data Engineers Team;
-
We also use Airflow for extracting data from external data sources. If they provide an API, we can extract .csv, .parquet files, or regular JSON API responses.
\
Quick results
- We launched our first stable DWH in just 6 months — from design to the complete migration of all analytical processes and analysts’ daily work out of the data swamp;
- We resolved data synchronisation from the primary authoritative system with minimal, near-real-time latency;
- We laid the foundation for differentiated access levels to data and resources across different user groups;
- The business started receiving high-quality analytics and added value through ML models, for which the DWH also serves as a source of reliable data.
\
PS
I’d like to add that this was only our initial architecture — you could call it an MVP.
We deliberately did not dive into creating additional data layers for modeling; our primary goal was to move quickly from a data swamp with uncontrolled changes and consumption to a controlled structure that provides the required quality and consistency.
The real timeline for the described DWH architecture begins in mid-2022. By 2025 our DWH architecture has undergone many changes, which will be covered in a separate article in the series — I’m intentionally preserving the chronology of events to describe our ongoing journey.
\ Thank you!


You May Also Like

Senate moves on coinbase CLARITY Act as stablecoin

Lovable AI’s Astonishing Rise: Anton Osika Reveals Startup Secrets at Bitcoin World Disrupt 2025




