

XRP Price: A Short Squeeze Could Send XRP Soaring – Here’s What Needs to Happen
TLDR
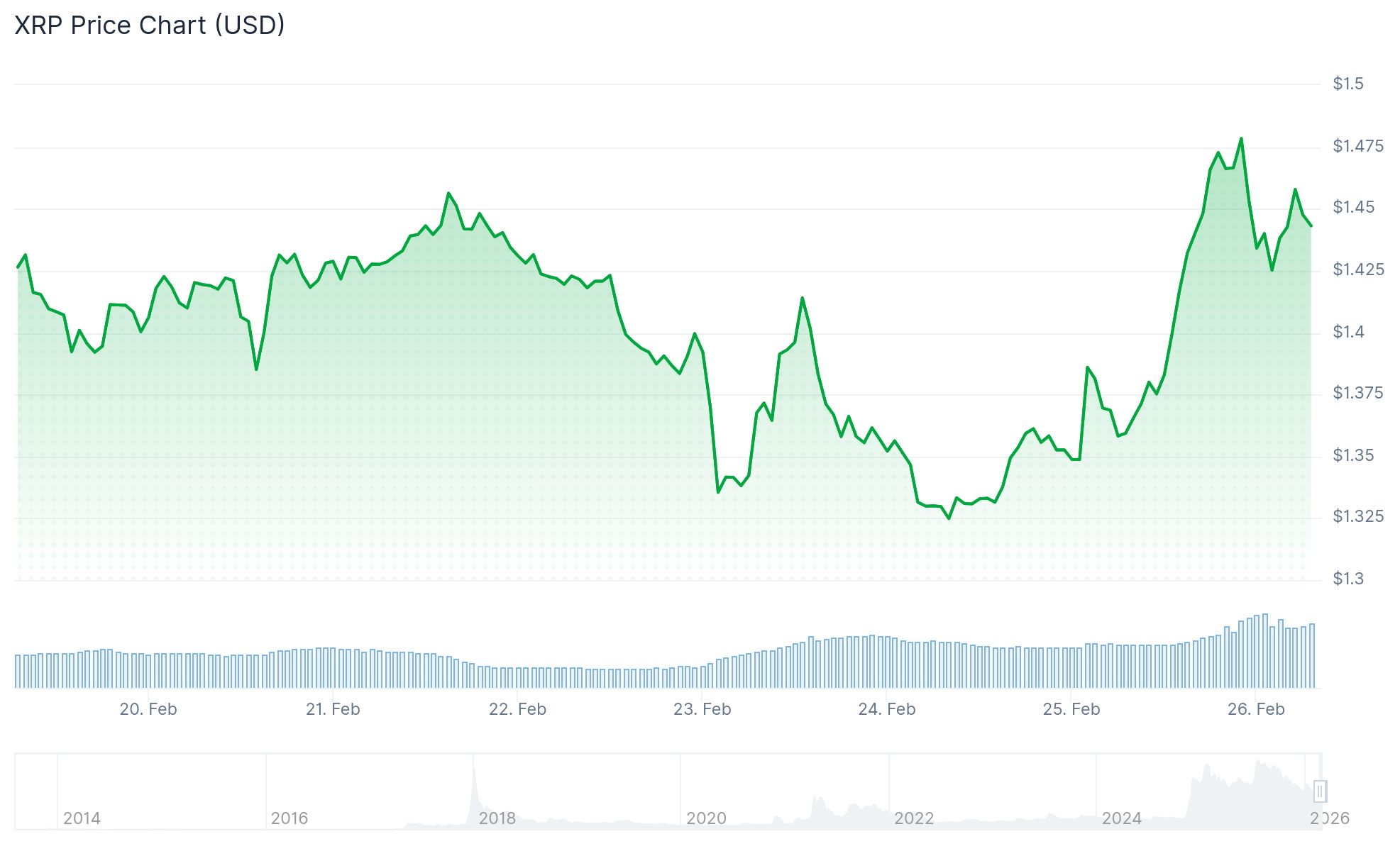
- XRP rebounded over 9% in 24 hours, trading around $1.46 after bouncing from support near $1.30
- Whale accumulation is increasing, with buy orders overwhelming sell orders according to on-chain data
- Key resistance levels sit at $1.49–$1.52, then $1.68, before any move back toward $2
- A short squeeze above current price could accelerate gains, with some analysts eyeing $4.20
- SBI Ripple Asia and DSRV Labs announced a collaboration to research XRP Ledger for cross-border payments between Japan and Korea
XRP has bounced nearly 9% from recent lows, trading around $1.46 after holding support near $1.30. The recovery lines up with a broader crypto market rebound, with Bitcoin pushing back above $68,000 and the total crypto market cap rising over 5% to around $2.37 trillion.
 XRP Price
XRP Price
Three days ago, analyst Cypress Demanincor flagged $1.3475 as a key daily buy wall when XRP was trading at $1.34. He said if buyers could hold that level, momentum could shift back to the bulls. His upside target range at the time was $1.45 to $1.99. XRP has now hit the lower end of that range.
In a follow-up update, Demanincor laid out the next levels to watch. As long as XRP holds above $1.40, the $1.49–$1.52 zone is the next hurdle. A clean break there would open the door to the sell wall at $1.68. Clearing $1.68 puts $2 back in play.
If buying pressure fades, $1.40 becomes the key support to watch. A break below that level could push XRP back toward $1.35.
$1.50 Is the Level to Watch
Analyst CryptoInsightUK echoed the importance of $1.50, saying he wants to see a daily close above that level to confirm a strong move. He noted the current bounce looks healthy and does not appear to be driven purely by open interest or manipulation.
On the technical side, XRP broke above a bearish trend line with resistance at $1.3820 on the hourly chart. The price reached a high of $1.4936 before consolidating. It is now trading above the 100-hourly Simple Moving Average. The MACD has shown a bullish crossover, and the RSI is approaching 70 without reaching extreme overbought territory.
Trading volume for XRP rose 26.69% in 24 hours to $3.53 billion, reflecting increased market participation.
Whale Activity and Short Squeeze Setup
On-chain data shows a sharp rise in large-scale buying. The Cumulative Volume Delta indicator points to buy orders consistently overwhelming sell orders. Analyst CW described the activity as aggressive, whale-driven accumulation.
Liquidity data highlighted by analyst Bird shows most downside levels have already been swept. Above current price, the market is stacked with short positions. If XRP continues rising, those short sellers would need to buy back at higher prices, adding further upward pressure. Bird sees a potential short squeeze that could push XRP toward $4.20.
On the institutional side, SBI Ripple Asia and South Korea’s DSRV Labs announced a research collaboration on February 24 to assess the XRP Ledger for cross-border payments between Japan and Korea.
XRP is currently trading around $1.46, with $1.49–$1.52 as the next key resistance zone to clear.
The post XRP Price: A Short Squeeze Could Send XRP Soaring – Here’s What Needs to Happen appeared first on CoinCentral.


You May Also Like

Sterling Weakens As Dollar Soars On Geopolitical Escalation And Bailey’s Cautious Stance
Crypto mining stocks suffer brutal quarterly slump




