

Ripple Déjà Vu? XRP Mirrors 2017 Pattern Before Massive Rally
XRP is forming a chart pattern that resembles its behavior before the 2017 rally. Analysts are watching this development as the market tests key levels seen in the last major price surge.
Current movements are taking place inside a long-standing channel structure that has guided XRP’s price action for over a decade.
Price Moves Within Long-Term Channel
A monthly chart shared by EtherNasyonaL shows Ripple’s token trading inside an upward-sloping channel that dates back to 2014. This structure includes lower support, a central median band, and an upper boundary. Price movements have consistently reacted to these levels.
In Q4 2017, XRP broke above the middle of this channel, then surged after a short period of sideways movement. The pattern eventually led to a peak near $3. A similar setup is forming in Q4 2025. XRP recently touched the middle band again, faced rejection, and is now consolidating below that level. The analyst commented,
At the time of writing, XRP trades at $2.44, with over $3 billion in daily volume, showing strong market activity during this phase.
Chart Projects $9.90 Target
Another chart from Javon Marks compares the current setup with the 2017 breakout. It uses historical moves and Fibonacci extensions to forecast future price zones. The next level in focus is $9.90, which would mark a 310% rise from current prices.
While other targets are plotted above this, most focus remains on whether XRP can clear nearby resistance and continue higher.
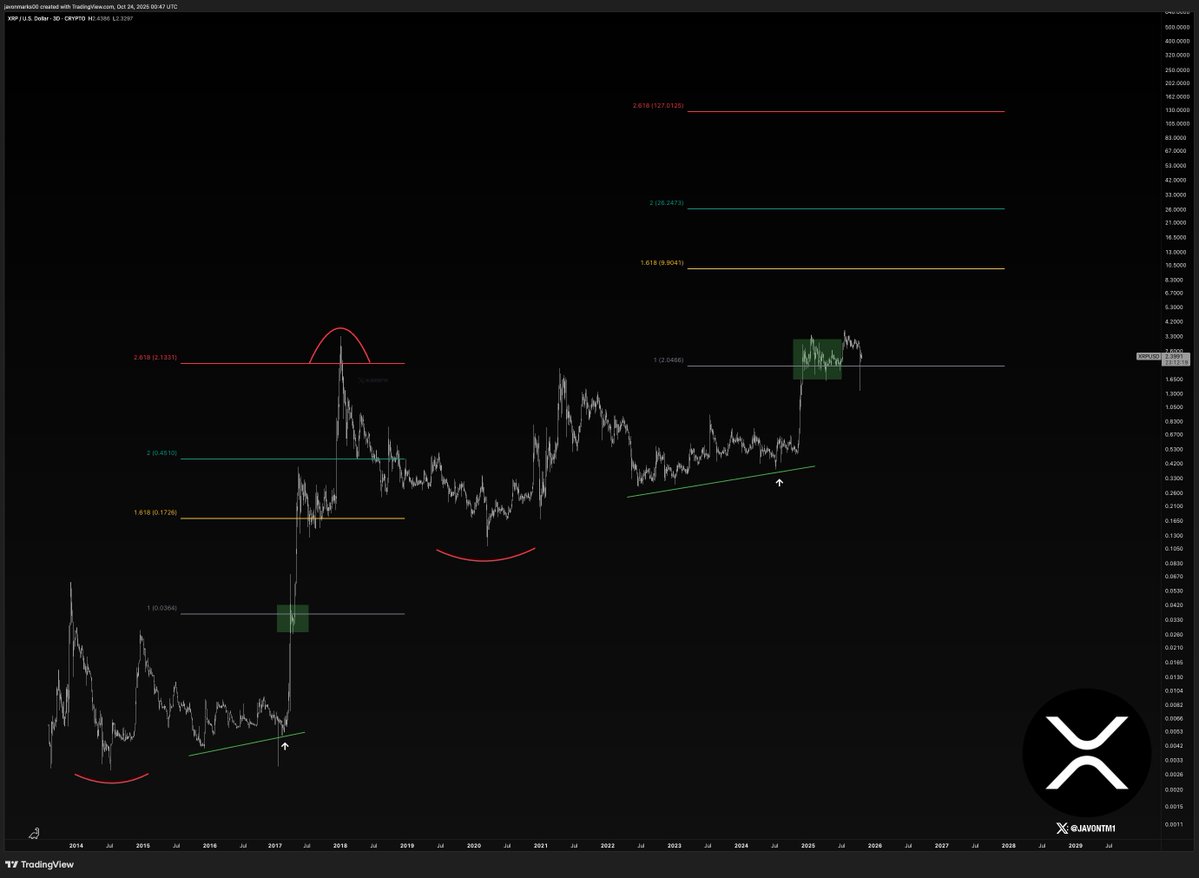 Source: Javon Marks/X
Source: Javon Marks/X
In addition, CRYPTOWZRD posted a daily technical update showing that XRP closed the session with no clear direction. The token remains near its daily support. A break to the upside depends on Bitcoin’s behavior, especially its dominance across the market. Resistance is marked at $2.75, with support sitting near $2.27.
Short-term charts suggest a possible dip to $2.3. A bounce from that level could lead to a move toward $2.55. Below $2.3, the chart turns bearish.
Large Holders Move Coins to Exchanges
On-chain data shows that wallets holding over one billion XRP have transferred around 1.09 billion tokens since October 16, as CryptoPotato recently reported. The move suggests that large holders may be taking profits or reducing exposure.
Such whale activity often signals caution, especially when paired with high-volume exchange inflows. Traders are watching these movements, as they may affect price direction. Meanwhile, Ali Martinez noted that the TD Sequential indicator has now printed a buy signal on the XRP chart.
The post Ripple Déjà Vu? XRP Mirrors 2017 Pattern Before Massive Rally appeared first on CryptoPotato.
You May Also Like

Pi Network Completes Mandatory v20.2 Protocol Upgrade: Preparing for Pi Day and a New Era of Utility

Pentagon Blocks Anthropic’s Claude AI Over Constitutional Policy Concerns
