

新規IIL設定:新しいデータのみでデプロイされたモデルを強化
リンク一覧
概要と1 はじめに
-
関連研究
-
問題設定
-
方法論
4.1. 決定境界を考慮した蒸留
4.2. 知識の統合
-
実験結果と5.1. 実験セットアップ
5.2. 最先端手法との比較
5.3. アブレーション研究
-
結論と今後の課題および参考文献
\
補足資料
- IILにおけるKCEMAメカニズムの理論的分析の詳細
- アルゴリズム概要
- データセットの詳細
- 実装の詳細
- ダスト処理された入力画像の可視化
- その他の実験結果
3. 問題設定
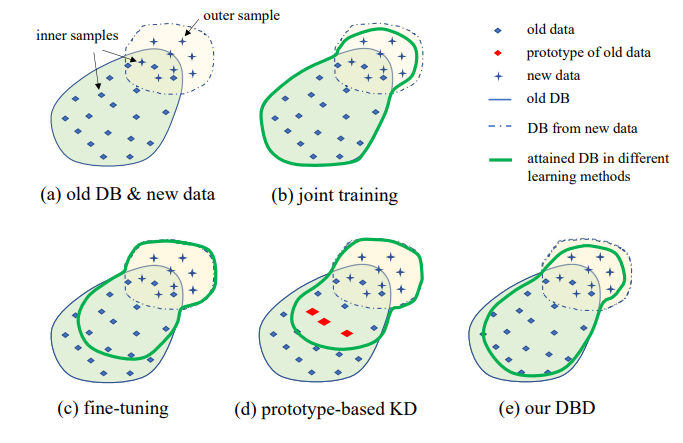
提案されたIIL設定の図解は図1に示されています。見てわかるように、データはデータストリームにおいて継続的かつ予測不可能に生成されます。一般的な実際のアプリケーションでは、人々はまず十分なデータを収集し、展開のための強力なモデルM0を訓練する傾向があります。モデルがどれほど強力であっても、分布外のデータに遭遇して失敗することは避けられません。これらの失敗したケースや他の低スコアの新しい観測値は、時々モデルを訓練するために注釈が付けられます。毎回蓄積されたすべてのデータでモデルを再訓練することは、時間とリソースのコストが高くなります。したがって、新しいIILは、毎回新しいデータのみを使用して既存のモデルを強化することを目指しています。
\ 
\ 
\
:::info 著者:
(1) Qiang Nie, 香港科技大学(広州);
(2) Weifu Fu, テンセントYoutuラボ;
(3) Yuhuan Lin, テンセントYoutuラボ;
(4) Jialin Li, テンセントYoutuラボ;
(5) Yifeng Zhou, テンセントYoutuラボ;
(6) Yong Liu, テンセントYoutuラボ;
(7) Qiang Nie, 香港科技大学(広州);
(8) Chengjie Wang, テンセントYoutuラボ.
:::
:::info この論文はarxivで入手可能であり、CC BY-NC-ND 4.0 Deed(帰属-非営利-改変禁止 4.0 国際)ライセンスの下で提供されています。
:::
\
関連コンテンツ

ピーター・ブラント氏が米国暗号資産法案はゲームチェンジャーにはならないと語る理由

利下げ失敗でビットコインラリーに火がつかず;オプション満期が迫る AI: 利下げ失敗でビットコインラリーに火がつかず;オプション満期が迫る
