

ハイブリッドAIモデルがメモリと効率性のバランスを取る方法
リンク一覧
概要と1. はじめに
-
方法論
-
実験と結果
3.1 高品質データによる言語モデリング
3.2 アテンションと線形回帰の探索
3.3 効率的な長さの外挿
3.4 長文脈理解
-
分析
-
結論、謝辞、参考文献
A. 実装の詳細
B. 追加実験結果
C. エントロピー測定の詳細
D. 制限事項
\
A 実装の詳細
\ スライディングGLAアーキテクチャのGLAレイヤーでは、ヘッド数dm/384、キー拡張率0.5、値拡張率1を使用しています。RetNetレイヤーでは、アテンションクエリヘッド数の半分のヘッド数、キー拡張率1、値拡張率2を使用しています。GLAとRetNetの実装はFlash Linear Attentionリポジトリ[3] [YZ24]からのものです。Self-Extend外挿にはFlashAttentionベースの実装を使用しています[4]。Mamba 432Mモデルはモデル幅1024、Mamba 1.3Bモデルはモデル幅2048を持っています。特に指定がない限り、SlimPajamaで訓練されたすべてのモデルは、Sambaと同じ訓練構成とMLP中間サイズを持っています。SlimPajamaでの訓練インフラストラクチャは、TinyLlamaコードベース[5]の修正版に基づいています。
\ 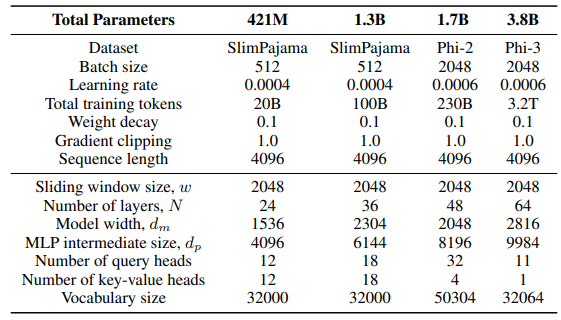
\ ダウンストリームタスクの生成設定では、GSM8Kにはgreedy decodingを使用し、HumanEvalには温度τ = 0.2、top-p = 0.95のNucleus Sampling [HBD+19]を使用しています。MBPPとSQuADでは、τ = 0.01、top-p = 0.95を設定しています。
B 追加実験結果
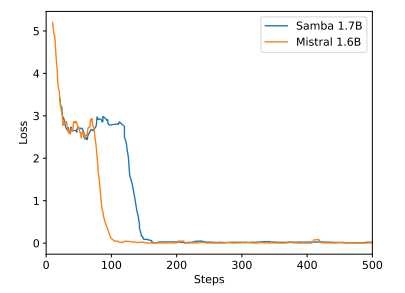
\ 
\ 
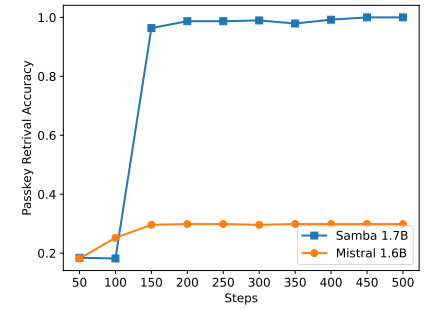
\ 
\
C エントロピー測定の詳細
\ 
\
D 制限事項
Sambaは指示調整を通じて有望なメモリ検索性能を示していますが、その事前訓練されたベースモデルは図7に示すように、SWAベースのモデルと同様の検索性能を持っています。これは、Sambaの効率性と外挿能力を損なうことなく、その検索能力をさらに向上させるための将来の方向性を開きます。さらに、Sambaのハイブリッド化戦略は、すべてのタスクで他の代替手段よりも一貫して優れているわけではありません。表2に示すように、MambaSWA-MLPはWinoGrande、SIQA、GSM8Kなどのタスクで性能が向上しています。これにより、SWAベースとSSMベースのモデルの入力依存の動的組み合わせを実行するためのより洗練されたアプローチに投資する可能性があります。
\
:::info 著者:
(1) Liliang Ren、Microsoftおよびイリノイ大学アーバナ・シャンペーン校 (liliangren@microsoft.com);
(2) Yang Liu†、Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†、Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen、Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang、Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen、Microsoft (wzchen@microsoft.com).
:::
:::info この論文は arxivで入手可能 でCC BY 4.0ライセンスの下で公開されています。
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
関連コンテンツ

VanEckのAVAXスポットETF(VAVX)、コインベース・クリプト・サービス経由で保有資産の70%をステーキングし、4%のステーキングサービス手数料で利回りを獲得

イーロン・マスクの資産、デラウェア州最高裁がテスラ株式オプションを復活させ7490億ドルに急増
