

التفاصيل التقنية: تدريب BSGAL، العمود الفقري Swin-L، واستراتيجية العتبة الديناميكية
جدول الروابط
نبذة مختصرة و1 مقدمة
-
الأعمال ذات الصلة
2.1. تعزيز البيانات التوليدية
2.2. التعلم النشط وتحليل البيانات
-
تمهيد
-
طريقتنا
4.1. تقدير المساهمة في السيناريو المثالي
4.2. التعلم النشط التوليدي المتدفق بالدفعات
-
التجارب و5.1. الإعداد غير المتصل
5.2. الإعداد المتصل
-
الخاتمة، التأثير الأوسع، والمراجع
\
أ. تفاصيل التنفيذ
ب. المزيد من الاختبارات
ج. مناقشة
د. التصور
أ. تفاصيل التنفيذ
أ.1. مجموعة البيانات
اخترنا LVIS (Gupta et al., 2019) كمجموعة بيانات لتجاربنا. LVIS هي مجموعة بيانات واسعة النطاق لتجزئة الكائنات، تتكون من حوالي 160,000 صورة مع أكثر من 2 مليون تعليق توضيحي عالي الجودة لتجزئة الكائنات عبر 1203 فئة من العالم الحقيقي. تنقسم مجموعة البيانات إلى ثلاث فئات: نادرة، شائعة، ومتكررة، بناءً على ظهورها عبر الصور. الكائنات المصنفة كـ "نادرة" تظهر في 1-10 صور، والكائنات "الشائعة" تظهر في 11-100 صورة، بينما تظهر الكائنات "المتكررة" في أكثر من 100 صورة. تُظهر مجموعة البيانات الكاملة توزيعًا طويل الذيل، يشبه بشكل كبير توزيع البيانات في العالم الحقيقي، ويتم تطبيقها على نطاق واسع تحت إعدادات متعددة، بما في ذلك تجزئة قليلة اللقطات (Liu et al., 2023) وتجزئة العالم المفتوح (Wang et al., 2022; Zhu et al., 2023). لذلك، نعتقد أن اختيار LVIS يسمح بانعكاس أفضل لأداء النموذج في سيناريوهات العالم الحقيقي. نستخدم تقسيمات مجموعة بيانات LVIS الرسمية، مع حوالي 100,000 صورة في مجموعة التدريب و20,000 صورة في مجموعة التحقق.
أ.2. توليد البيانات
تتوافق عملية توليد البيانات والتعليق التوضيحي لدينا مع Zhao et al. (2023)، ونقدم هنا مقدمة موجزة. نستخدم أولاً StableDiffusion V1.5 (Rombach et al., 2022a) (SD) كنموذج توليدي. للفئات الـ 1203 في LVIS (Gupta et al., 2019)، نقوم بتوليد 1000 صورة لكل فئة، بدقة صورة 512 × 512. قالب الإرشاد للتوليد هو "صورة لـ {اسم الفئة} واحد". نستخدم U2Net (Qin et al., 2020)، وSelfReformer (Yun and Lin, 2022)، وUFO (Su et al., 2023)، وCLIPseg (Luddecke and Ecker ¨ , 2022) على التوالي لتعليق الصور التوليدية الخام، ونختار القناع ذو أعلى درجة CLIP كتعليق توضيحي نهائي. لضمان جودة البيانات، يتم تصفية الصور ذات درجات CLIP أقل من 0.21 كصور منخفضة الجودة. أثناء التدريب، نستخدم أيضًا استراتيجية لصق الكائنات المقدمة من Zhao et al. (2023) لتعزيز البيانات. لكل كائن، نقوم بتغيير حجمه عشوائيًا ليتناسب مع توزيع فئته في مجموعة التدريب. الحد الأقصى لعدد الكائنات الملصقة لكل صورة هو 20.
\ بالإضافة إلى ذلك، لزيادة تنوع البيانات المولدة وجعل بحثنا أكثر عالمية، نستخدم أيضًا نماذج توليدية أخرى، بما في ذلك DeepFloyd-IF (Shonenkov et al., 2023) (IF) وPerfusion (Tewel et al., 2023) (PER)، مع 500 صورة لكل فئة لكل نموذج. بالنسبة لـ IF، نستخدم النموذج المدرب مسبقًا المقدم من المؤلف، والصور المولدة هي مخرجات المرحلة الثانية، بدقة 256×256. بالنسبة لـ PER، النموذج الأساسي الذي نستخدمه هو StableDiffusion V1.5. لكل فئة، نقوم بضبط النموذج باستخدام الصور المقتطعة من مجموعة التدريب، مع 400 خطوة ضبط دقيق. نستخدم النموذج المضبوط لتوليد الصور.
\ 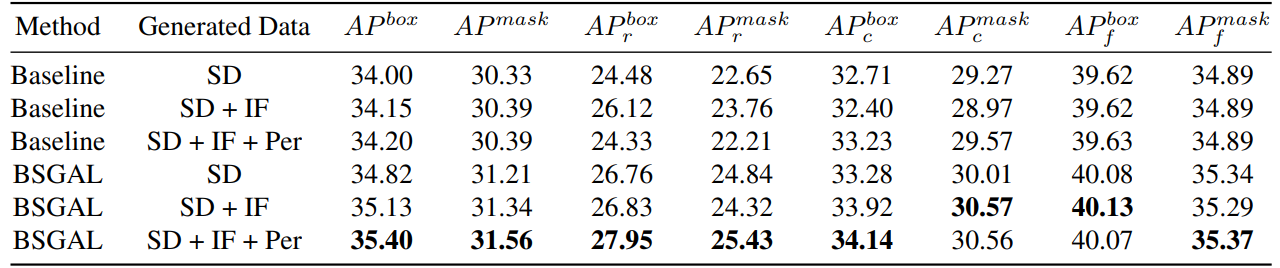
\ نستكشف أيضًا تأثير استخدام بيانات مولدة مختلفة على أداء النموذج (انظر الجدول 7). يمكننا أن نرى أنه بناءً على StableDiffusion V1.5 الأصلي، يمكن أن يؤدي استخدام نماذج توليدية أخرى إلى تحسين الأداء، لكن هذا التحسين ليس واضحًا. على وجه التحديد، بالنسبة لفئات التردد المحددة، وجدنا أن IF لديه تحسين أكثر أهمية للفئات النادرة، بينما PER لديه تحسين أكثر أهمية للفئات الشائعة. من المحتمل أن يكون هذا لأن بيانات IF أكثر تنوعًا، بينما بيانات PER أكثر اتساقًا مع توزيع مجموعة التدريب. بالنظر إلى أن الأداء العام قد تحسن إلى حد معين، فإننا نتبنى في النهاية البيانات المولدة من SD + IF + PER للتجارب اللاحقة.
أ.3. تدريب النموذج
اتباعًا لـ Zhao et al. (2023)، نستخدم CenterNet2 (Zhou et al., 2021) كنموذج التجزئة لدينا، مع ResNet-50 (He et al., 2016) أو Swin-L (Liu et al., 2022) كعمود فقري. بالنسبة لـ ResNet-50، يتم تعيين الحد الأقصى لتكرار التدريب إلى 90,000 ويتم تهيئة النموذج بأوزان مدربة مسبقًا أولاً على ImageNet-22k ثم ضبطها على LVIS (Gupta et al., 2019)، كما فعل Zhao
\ 
\ et al. (2023). ونستخدم 4 وحدات معالجة رسومات Nvidia 4090 مع حجم دفعة 16 أثناء التدريب. أما بالنسبة لـ Swin-L، فيتم تعيين الحد الأقصى لتكرار التدريب إلى 180,000 ويتم تهيئة النموذج بأوزان مدربة مسبقًا على ImageNet-22k، حيث أظهرت تجاربنا المبكرة أن هذه التهيئة يمكن أن تجلب تحسينًا طفيفًا مقارنة بالأوزان المدربة مع LVIS. ونستخدم 4 وحدات معالجة رسومات Nvidia A100 مع حجم دفعة 16 للتدريب. بالإضافة إلى ذلك، نظرًا للعدد الكبير من المعلمات في Swin-L، فإن الذاكرة الإضافية التي تشغلها حفظ التدرج كبيرة، لذلك نستخدم فعليًا الخوارزمية في الخوارزمية 2.
\ تتبع المعلمات الأخرى غير المحددة أيضًا نفس إعدادات X-Paste (Zhao et al., 2023)، مثل محسن AdamW (Loshchilov and Hutter, 2017) مع معدل تعلم أولي قدره 1e−4.
أ.4. كمية البيانات
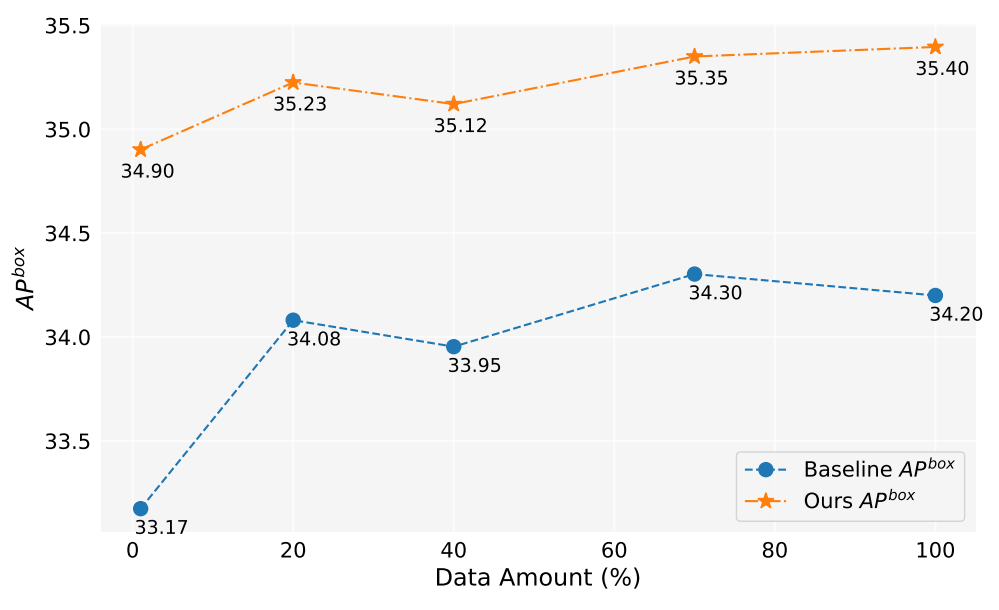
في هذا العمل، قمنا بتوليد أكثر من 2 مليون صورة. يوضح الشكل 5 أداء النموذج عند استخدام كميات مختلفة من البيانات المولدة (1%، 10%، 40%، 70%، 100%). بشكل عام، مع زيادة كمية البيانات المولدة، يتحسن أداء النموذج أيضًا، ولكن هناك أيضًا بعض التقلبات. طريقتنا دائمًا أفضل من الخط الأساسي، مما يثبت فعالية ومتانة طريقتنا.
أ.5. تقدير المساهمة
\ وبالتالي، نحن نحسب أساسًا تشابه جيب التمام. ثم أجرينا مقارنة تجريبية، كما هو موضح في الجدول 8،
\ 
\ 
\ يمكننا أن نرى أنه إذا قمنا بتطبيع التدرج، فستحقق طريقتنا تحسينًا معينًا. بالإضافة إلى ذلك، نظرًا لأننا بحاجة إلى الاحتفاظ بعتبتين مختلفتين، فمن الصعب ضمان اتساق معدل القبول. لذلك نتبنى استراتيجية عتبة ديناميكية، نحدد مسبقًا معدل قبول، ونحتفظ بقائمة انتظار لحفظ مساهمة التكرار السابق، ثم نعدل العتبة ديناميكيًا وفقًا لقائمة الانتظار، بحيث يبقى معدل القبول عند معدل القبول المحدد مسبقًا.
أ.6. تجربة لعبة
فيما يلي إعدادات التجربة المحددة المنفذة على CIFAR-10: استخدمنا ResNet18 البسيط كنموذج أساسي وأجرينا تدريبًا على مدار 200 عصر، والدقة بعد التدريب على مجموعة التدريب الأصلية هي 93.02%. تم تعيين معدل التعلم عند 0.1، باستخدام محسن SGD. يتم تطبيق زخم 0.9، مع تضاؤل وزن 5e-4. نستخدم جدول معدل تعلم تخميد جيبي. يتم تصوير الصور الضوضائية المنشأة في الشكل 6. يلاحظ انخفاض في جودة الصورة مع تصاعد مستوى الضوضاء. جدير بالذكر أنه عندما يصل مستوى الضوضاء إلى 200، تصبح الصور صعبة التحديد بشكل كبير. بالنسبة للجدول 1، نستخدم Split1 كـ R، بينما يتكون G من 'Split2 + Noise40'، 'Split3 + Noise100'، 'Split4 + Noise200'،
أ.7. تبسيط للأمام مرة واحدة فقط
\
:::info المؤلفون:
(1) موزي تشو، بمساهمة متساوية من جامعة تشجيانغ، الصين؛
(2) تشنغشيانغ فان، بمساهمة متساوية من جامعة تشجيانغ، الصين؛
(3) هاو تشن، جامعة تشجيانغ، الصين (haochen.cad@zju.edu.cn)؛
(4) يانغ ليو، جامعة تشجيانغ، الصين؛
(5) ويان ماو، جامعة تشجيانغ، الصين وجامعة أديلايد، أستراليا؛
(6) شياوغانغ شو، جامعة تشجيانغ، الصين؛
(7) تشونهوا شن، جامعة تشجيانغ، الصين (chunhuashen@zju.edu.cn).
:::
:::info هذه الورقة متاحة على arxiv تحت رخصة CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\


قد يعجبك أيضاً

هولوجيك (HOLX) تتحول إلى شركة خاصة: بلاكستون وTPG تختتمان صفقة استحواذ بقيمة 17 مليار دولار

تهوي أسهم شركة أكسون إنتربرايز (AXON) إلى أدنى مستوى في 52 أسبوعًا وسط مخاوف قانونية وتخفيضات السعر المستهدف




