

Làm thế nào Mixture-of-Adaptations Giúp Fine-Tuning Mô hình Ngôn ngữ Rẻ hơn và Thông minh hơn
Bảng liên kết
Tóm tắt và 1. Giới thiệu
-
Nền tảng
2.1 Mixture-of-Experts
2.2 Adapters
-
Mixture-of-Adaptations
3.1 Chính sách định tuyến
3.2 Điều chuẩn nhất quán
3.3 Hợp nhất mô-đun thích ứng và 3.4 Chia sẻ mô-đun thích ứng
3.5 Kết nối với Mạng thần kinh Bayesian và Mô hình tổng hợp
-
Thí nghiệm
4.1 Thiết lập thí nghiệm
4.2 Kết quả chính
4.3 Nghiên cứu loại bỏ
-
Công trình liên quan
-
Kết luận
-
Hạn chế
-
Lời cảm ơn và Tài liệu tham khảo
Phụ lục
A. Bộ dữ liệu NLU ít mẫu B. Nghiên cứu loại bỏ C. Kết quả chi tiết trên các tác vụ NLU D. Siêu tham số
3 Mixture-of-Adaptations

\
3.1 Chính sách định tuyến
Các công trình gần đây như THOR (Zuo et al., 2021) đã chứng minh chính sách định tuyến ngẫu nhiên hoạt động hiệu quả tương đương với cơ chế định tuyến cổ điển như Switch routing (Fedus et al., 2021) với những lợi ích sau. Vì các mẫu đầu vào được định tuyến ngẫu nhiên đến các chuyên gia khác nhau, không cần cân bằng tải bổ sung vì mỗi chuyên gia có cơ hội bình đẳng được kích hoạt, đơn giản hóa khuôn khổ. Hơn nữa, không có tham số bổ sung, và do đó không có tính toán thêm, tại lớp Switch để lựa chọn chuyên gia. Điều sau đặc biệt quan trọng trong thiết lập của chúng tôi để tinh chỉnh hiệu quả tham số, giữ cho tham số và FLOPs giống như của một mô-đun thích ứng đơn lẻ. Để phân tích hoạt động của AdaMix, chúng tôi chứng minh kết nối giữa định tuyến ngẫu nhiên và trung bình hóa trọng số mô hình với Mạng thần kinh Bayesian và mô hình tổng hợp trong Phần 3.5.
\ \ 
\ \ Định tuyến ngẫu nhiên như vậy cho phép các mô-đun thích ứng học các phép biến đổi khác nhau trong quá trình huấn luyện và thu được nhiều góc nhìn về tác vụ. Tuy nhiên, điều này cũng tạo ra thách thức về việc sử dụng mô-đun nào trong quá trình suy luận do giao thức định tuyến ngẫu nhiên trong quá trình huấn luyện. Chúng tôi giải quyết thách thức này với hai kỹ thuật sau, cho phép chúng tôi thu gọn các mô-đun thích ứng và đạt được chi phí tính toán tương tự (FLOPs, số tham số thích ứng có thể điều chỉnh) như của một mô-đun đơn lẻ.
3.2 Điều chuẩn nhất quán
\ 
\ \ \ 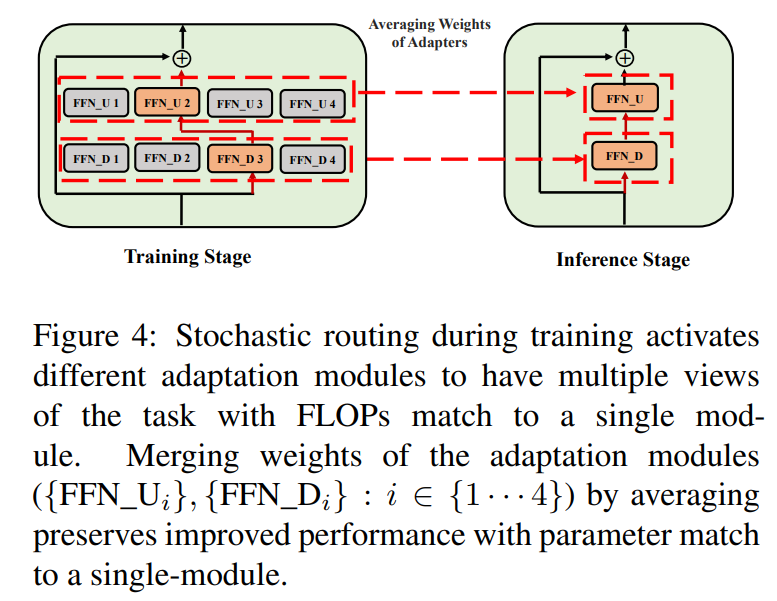
3.3 Hợp nhất mô-đun thích ứng
Mặc dù điều chuẩn trên giảm thiểu sự không nhất quán trong việc lựa chọn mô-đun ngẫu nhiên trong quá trình suy luận, nó vẫn dẫn đến chi phí phục vụ tăng lên để lưu trữ nhiều mô-đun thích ứng. Các công trình trước đây trong việc tinh chỉnh mô hình ngôn ngữ cho các tác vụ hạ nguồn đã cho thấy hiệu suất cải thiện khi trung bình hóa trọng số của các mô hình tinh chỉnh khác nhau với các hạt giống ngẫu nhiên khác nhau, vượt trội hơn một mô hình tinh chỉnh đơn lẻ. Công trình gần đây (Wortsman et al., 2022) cũng đã chỉ ra rằng các mô hình tinh chỉnh khác nhau từ cùng một khởi tạo nằm trong cùng một lưu vực lỗi, thúc đẩy việc sử dụng tổng hợp trọng số cho việc tóm tắt tác vụ mạnh mẽ. Chúng tôi áp dụng và mở rộng các kỹ thuật trước đây cho việc tinh chỉnh mô hình ngôn ngữ vào quá trình huấn luyện hiệu quả tham số của các mô-đun thích ứng đa góc nhìn
\ \ 
\
3.4 Chia sẻ mô-đun thích ứng
\ 
3.5 Kết nối với Mạng thần kinh Bayesian và Mô hình tổng hợp
\ 
\ \ Điều này đòi hỏi phải tính trung bình trên tất cả các trọng số mô hình có thể, điều này không khả thi trong thực tế. Do đó, một số phương pháp xấp xỉ đã được phát triển dựa trên các phương pháp suy luận biến phân và kỹ thuật điều chuẩn ngẫu nhiên sử dụng dropouts. Trong công trình này, chúng tôi tận dụng một điều chuẩn ngẫu nhiên khác dưới dạng định tuyến ngẫu nhiên. Ở đây, mục tiêu là tìm một phân phối thay thế qθ(w) trong một họ phân phối khả thi có thể thay thế cho hậu nghiệm mô hình thực sự khó tính toán. Phân phối thay thế lý tưởng được xác định bằng cách tối thiểu hóa độ phân kỳ Kullback-Leibler (KL) giữa ứng viên và hậu nghiệm thực.
\ \ 
\ \ \ 
\ \ \ 
\ \ \ \
:::info Tác giả:
(1) Yaqing Wang, Đại học Purdue (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Đại học Purdue (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC BY 4.0 DEED.
:::
\
Có thể bạn cũng thích

BTC giảm xuống dưới 88.000 USD, giảm 0,22% trong ngày.

Vitalik Buterin ủng hộ thị trường dự đoán hơn mạng xã hội
