

Bittensor Jumps 13%; Is Hitting $300—Here’s What Next for the TAO Price Rally.

The post Bittensor Jumps 13%; Is Hitting $300—Here’s What Next for the TAO Price Rally. appeared first on Coinpedia Fintech News
Bittensor price has drawn strong market attention since February, rallying even as the broader market consolidated. Bulls stepped in aggressively below $250, driving TAO back toward a critical resistance zone. The token now trades near $304, up around 16.5%, as it retests the psychologically significant $300 level that has capped prior rallies.
The move is supported by a sharp 90% surge in 24-hour trading volume to $645 million, reflecting strong buying interest. However, momentum indicators point to overbought conditions, making the $300 zone pivotal—where a confirmed breakout, rejection, or reversal could shape the next long-term trend.
What’s Fueling Bittensor’s Rally?
Beyond price action, the move aligns with growing interest in the AI-crypto sector, where Bittensor continues to stand out due to its subnet-driven architecture. The expanding subnet ecosystem, accounting for a significant share of the network’s total valuation, reflects increasing demand for decentralized machine learning resources.
This suggests that the rally is not purely speculative but partially backed by network-level growth and capital rotation into AI-focused assets. However, the sustainability of this trend will depend on whether these metrics continue to expand. Sharp volume spikes and rapid price appreciation often precede short-term exhaustion, especially when momentum indicators already signal overbought conditions.
Can TAO Sustain Above $300? Key Levels to Watch
Bittensor price is now testing a major supply zone between $300 and $310, a level that has previously acted as a strong rejection area. The current move has pushed the price to around $306, marking a clean recovery from the February lows near $150–$170, translating to a nearly 80–90% upside rally in just a few weeks. The 200-day SMA, currently near $285, has been reclaimed, signalling a shift in macro trend bias toward bullish territory.
However, the TAO price is now extended above this average, increasing the probability of short-term mean reversion if momentum slows.
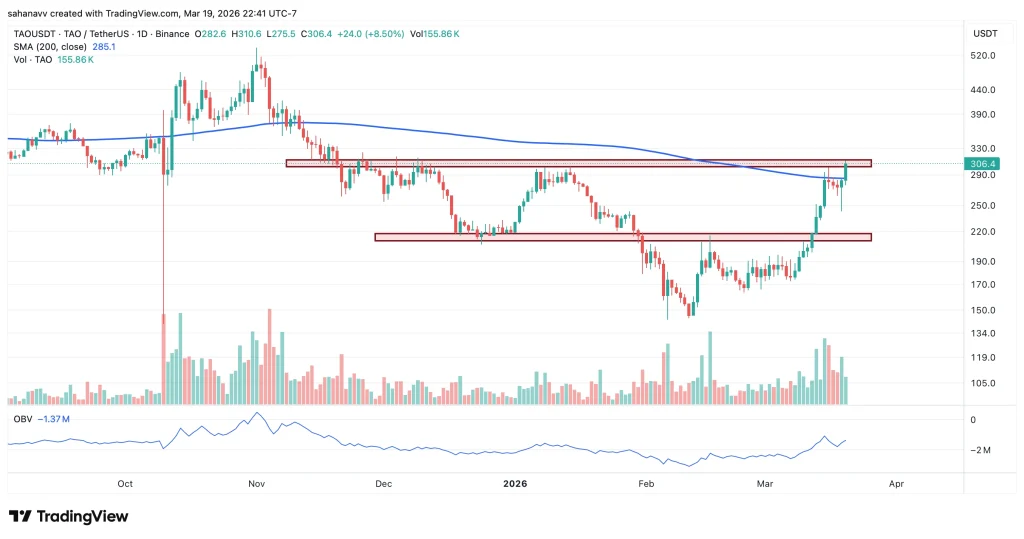
From a market structure perspective, this is the first higher high attempt after a prolonged downtrend, which makes this level structurally critical. Volume analysis supports the breakout attempt, as the recent candles show consistent volume expansion, not a single spike, which indicates sustained participation. Additionally, On-Balance Volume (OBV) is trending upward, confirming that buying pressure is gradually increasing, aligning with the price breakout attempt.
Key Scenarios
Bullish Case (Continuation):
- A confirmed daily close above $310
- Opens the path toward $340–$360 (next supply zone from prior structure)
Bearish Case (Rejection):
- Failure to hold above $300
- Likely pullback toward $260–$280 (previous consolidation + 200 SMA zone)
Breakdown Risk:
- If $260 fails, the price may revisit $220 support, which acted as a base during accumulation
Breakout or Bull Trap? The Decisive Moment for TAO
Bittensor’s rally is clearly backed by strong participation and a renewed AI-driven narrative, but the real test lies in whether this momentum can translate into sustained acceptance at higher levels. Sharp recoveries often attract late buyers, which can temporarily inflate price action without establishing long-term strength.
The broader setup presents a classic dilemma. On one hand, a near 90% recovery from February lows, rising volume, and an upward-trending OBV suggest that buyers remain in control. On the other hand, the price is now extended above key averages and testing a historically strong supply zone—conditions that often precede short-term exhaustion.
Ultimately, the next move will likely define the medium-term trend. Until a clear breakout is confirmed, the current rally of Bittensor (TAO) price remains promising—but unproven.


You May Also Like

Bitcoin Exchange Binance Announces New Listings on its Futures Platform! Here Are the Details
ESMA compliance internal audit funds review flags governance gaps




