

$5.4 Billion Left Binance and Bitfinex While ETFs Absorbed 45,700 BTC – The Supply and Demand Split Is Widening
On-chain data from CryptoQuant shows Bitcoin and Ethereum leaving major exchanges at an accelerating pace while U.S. spot ETFs added 45,700 BTC worth approximately $3.25 billion between February 24 and March 19, creating a structural divergence between where supply is going and where institutional demand is coming from.
What the Binance Cumulative Netflow Chart Shows
The first chart covers November 2024 through March 19, 2026, tracking cumulative BTC and ETH netflows on Binance in dollar value. The BTC flow in orange and ETH flow in purple both sit below the zero line for the majority of the visible period, indicating net outflows have been the dominant condition since late November.
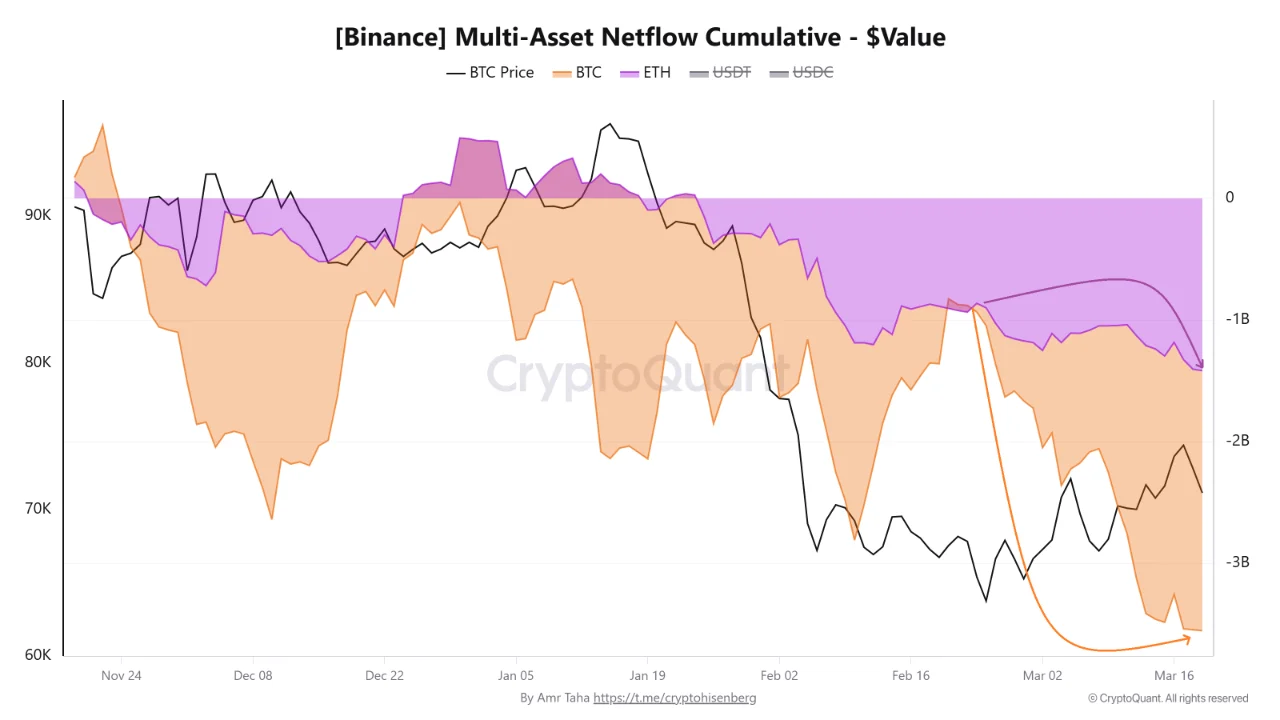 The BTC outflow trajectory accelerated sharply in February. Between February 21 and March 19, Bitcoin cumulative netflows on Binance shifted from approximately positive $55 million to negative $2.1 billion. That is a $2.155 billion swing in less than a month. The orange area on the chart drops steeply toward the lower right, reaching its deepest visible reading near March 16 before a slight recovery. The orange line at the very bottom right of the chart shows the most extreme cumulative outflow point of the entire tracked period.
The BTC outflow trajectory accelerated sharply in February. Between February 21 and March 19, Bitcoin cumulative netflows on Binance shifted from approximately positive $55 million to negative $2.1 billion. That is a $2.155 billion swing in less than a month. The orange area on the chart drops steeply toward the lower right, reaching its deepest visible reading near March 16 before a slight recovery. The orange line at the very bottom right of the chart shows the most extreme cumulative outflow point of the entire tracked period.
Ethereum followed the same direction with less severity. Cumulative ETH netflows moved from negative $935 million to negative $1.4 billion over the same window, an additional $465 million in outflows. The purple ETH area maintains its negative position throughout the chart period but has not recovered meaningfully since February. Both assets accelerating outflows simultaneously points toward coordinated large-holder behavior rather than asset-specific selling pressure.
What the Exchange Netflow Chart Shows
The second chart tracks daily BTC netflows across eight major exchanges from January 19 through mid-March 2026, with Binance in orange, OKX in purple, Bybit in grey, Kraken in blue, Bitfinex in green, Coinbase in light grey, Gemini in teal, and HTX Global in dark blue, alongside the BTC price line in black.
The two dominant events on this chart are both green Bitfinex bars. Around March 4, a green outflow bar drops to approximately negative $1.75 billion, annotated with a triangle marker at the bottom of the chart. Around March 16, a second green bar drops to approximately negative $1.57 billion, also annotated. Both spikes dwarf every other exchange’s daily netflow reading across the entire chart period. No other exchange comes close to those magnitudes on any single day.
The Binance orange bars show smaller but consistent net outflow readings throughout the period. The other exchanges produce mixed daily signals that largely cancel each other out. Bitfinex is the single largest driver of the combined $3.32 billion outflow figure across the two-week window. Combined with the Binance cumulative figure, total outflows from the two exchanges exceed $5.4 billion across the period covered.
Neither spike produced a price breakdown at the time of occurrence. The March 4 event coincided with price near $65,000 on the black line. The March 16 event occurred as price was recovering toward $73,000. Supply leaving exchanges at scale during a price recovery is more consistent with institutional positioning than with panic selling.
What the ETF Accumulation Chart Shows
The third chart covers late September 2024 through March 16, 2026, tracking BTC price in black against total U.S. spot ETF holdings in yellow, measured in BTC on the right axis. The yellow ETF holdings line peaked near 1.35 million BTC around October 2024, declined through the price drawdown period from November through February, and has since recovered to approximately 1.29 million to 1.30 million BTC.
The annotated figure on the chart identifies 45,700 BTC added to total ETF holdings between February 24 and March 19, equivalent to approximately $3.25 billion at an average price near $71,000. That accumulation occurred across the same window when exchange outflows were accelerating, when Bitcoin was trading between $63,000 and $74,000, and when daily ETF flow data showed individual sessions of significant outflows from specific issuers including Fidelity and BlackRock.
The apparent contradiction between the daily outflow data and the cumulative ETF holdings increase resolves when both timeframes are considered together. Single-day outflows reflect rebalancing and short-term positioning. The 24-day cumulative figure reflects the net direction of institutional positioning across the full window. The net direction was accumulation.
What the Three Charts Together Indicate
The data describes a market where supply is being systematically removed from exchange liquidity while institutional demand is absorbing it through ETF custody channels. BTC and ETH leaving Binance is not hitting the market as selling pressure. Bitfinex outflows at $1.75 billion and $1.57 billion are not appearing as ask-side volume on price charts. The supply is moving to cold storage and ETF custody rather than to new sellers.
That dynamic does not automatically translate into price appreciation on a specific timeline. Supply moving off exchanges reduces the available float but does not force buyers into the market. What it does is change the conditions under which price discovery occurs. A market with a shrinking exchange float and $3.25 billion in institutional accumulation across 24 days is structurally different from one where supply is freely available.
Price is currently below $70,000 under geopolitical and macro pressure. The on-chain structure underneath that price level tells a different story than the near-term chart does.
The post $5.4 Billion Left Binance and Bitfinex While ETFs Absorbed 45,700 BTC – The Supply and Demand Split Is Widening appeared first on ETHNews.


You May Also Like

Critical USDT0 Response to Drift Hack Exposes Stark Contrast in Stablecoin Security Protocols

Best Music AI Websites For Songs And Soundtracks




