

Generalization and Robustness: RECKONING Excels on Longer Reasoning Chains Unseen During Training
Table of Links
Abstract and 1. Introduction
-
Background
-
Method
-
Experiments
4.1 Multi-hop Reasoning Performance
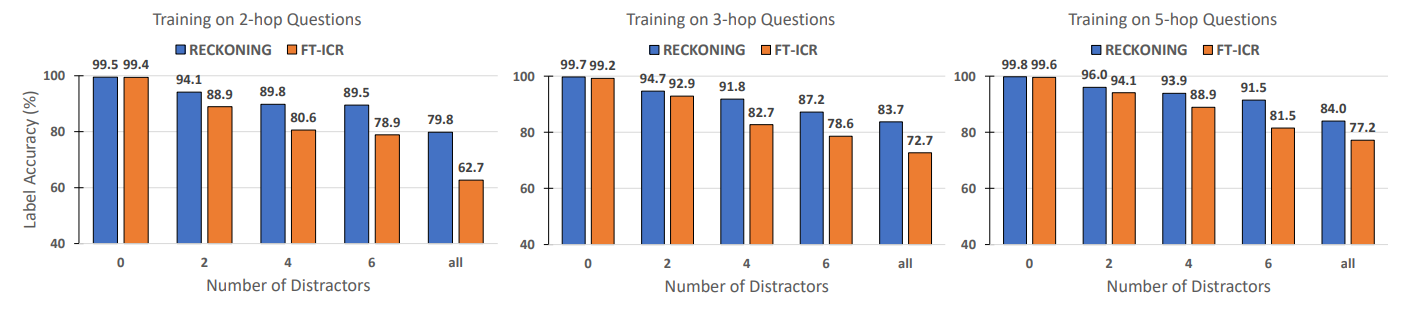
4.2 Reasoning with Distractors
4.3 Generalization to Real-World knowledge
4.4 Run-time Analysis
4.5 Memorizing Knowledge
-
Related Work
-
Conclusion, Acknowledgements, and References
\ A. Dataset
B. In-context Reasoning with Distractors
C. Implementation Details
D. Adaptive Learning Rate
E. Experiments with Large Language Models
4.1 Multi-hop Reasoning Performance
Main Results We first evaluate whether RECKONING learns to perform reasoning in the base setting. A model is given a set of supporting facts (without distractors) and a question (or hypothesis) as input and begins by performing a few CLM learning steps on the facts. Then, the updated model reads only the question and generates an answer. To answer correctly, the model must reason over both facts and the question, meaning it must encode the facts during the inner loop such that multi-hop reasoning can be performed over them later.
\ 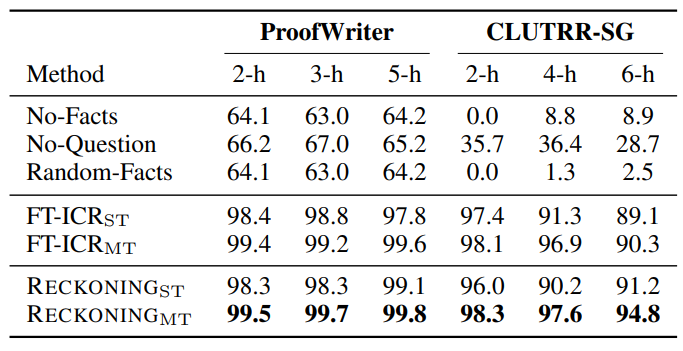
\ We train our models and the fine-tuned ICR (FT-ICR) baselines with both the single-task (LCE) and multi-task (LCE + LCLM) objectives. For multi-task (MT) training, the model learns to answer the question and generate its relevant knowledge in the outer loop. Table 1 shows the evaluation results on question answering (or hypothesis classification). For all hop numbers in ProofWriter and CLUTRR-SG, multi-task RECKONING outperforms the best result of all baselines (consistently obtained by multi-task FT-ICR) by an average of 1%. We conclude that RECKONING can effectively solve reasoning problems through its updated parametric knowledge and do so better than existing baselines. The multi-task objective is crucial for this success: not only is RECKONING’s performance consistently higher (by an average of 2.8% over the two datasets and their hop counts) when using the multi-task rather than single-task (ST) objective, but it also under-performs both FTICR baselines when trained with only the single-task objective. The multi-task objective also improves FT-ICR consistently (average 1.8%), though it is not enough to beat the multi-task RECKONING. In all further experiments, we consider only RECKONING and FT-ICR with a multi-task objective.
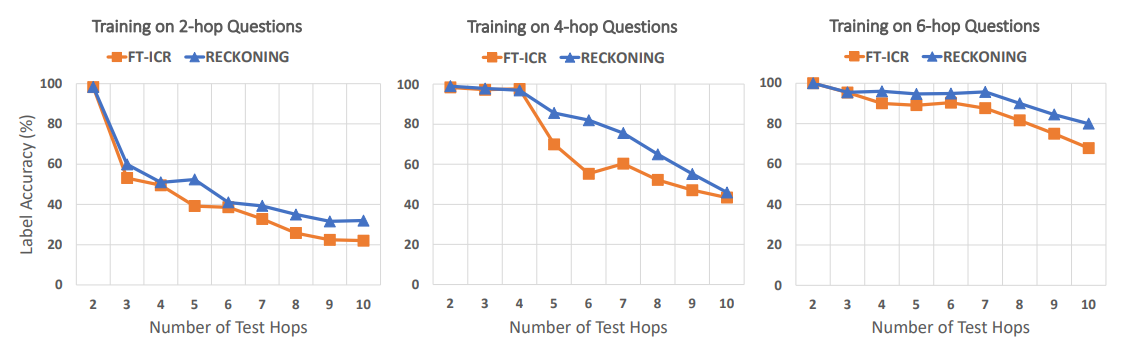
\ Generalizing to Longer Reasoning Chains Our first experiments assume an alignment between the number of reasoning hops in the questions in the training and test set. However, we may not be able to train on all n-hop reasoning questions we encounter in the wild, and we rarely know the number of reasoning hops in a question a priori. Consequently, we also measure the generalization capacity of our model to questions with hop numbers unseen during training. We compile interpolation (fewer hops than the train set) and extrapolation (more hops than the train set) test sets from the CLUTRRSG dataset. Again, we train models individually on 2-hop, 4-hop, and 6-hop examples and evaluate these three sets of models on the test sets, which contain 2-10-hop reasoning questions. Figure 3 shows that both RECKONING models and ICR baselines retain high performance on the interpolation test sets but exhibit decreasing performance as the number of hops increases. Importantly, though, RECKONING outperforms FT-ICR on all test sets regardless of the number of training hops, with the highest difference being more than 10% in every training setting (15%, 30%, 10%, respectively). These performance gains when testing on extrapolation data suggest that training with RECKONING better generalizes to examples with high OOD hop counts than in-context reasoning (ICR).
\ 
\ 
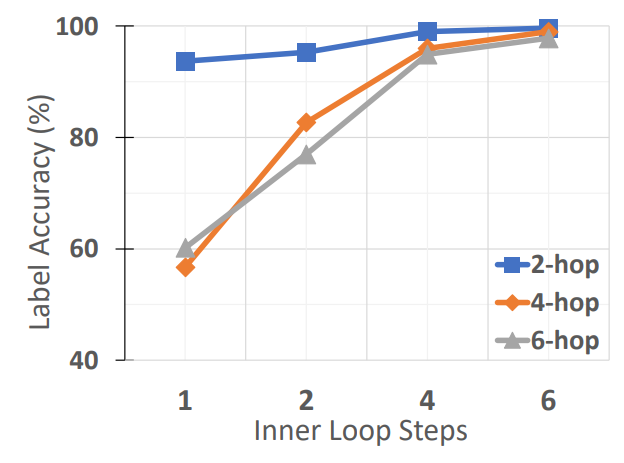
\ Does RECKONING’s performance depend on the number of inner loop gradient steps? In RECKONING, the model performs multi-hop reasoning over facts by encoding facts using multiple gradient steps in the inner loop optimization (§3). Naturally, this process prompts the question of whether there is a correlation between the number of reasoning hops and the number of gradient steps needed to reliably encode the knowledge (i.e., problems with more reasoning hops require more gradient steps in the inner loop to encode the facts). In Figure 4, we show for CLUTRR-SG that as the number of inner loop steps increases, the label accuracy of the outer-loop task also increases. Furthermore, when considering the performance gains for reasoning with 6 inner loop steps (i.e., knowledge encoding) as opposed to one, we observe that this gap is much more pronounced for 4-hop (42.3%) and 6-hop (34.7%) reasoning than it is for 2-hop reasoning (5.9%). These results show that problems requiring more hops of reasoning also greatly benefit from more steps of inner loop knowledge encoding.
\ 
\
:::info Authors:
(1) Zeming Chen, EPFL (zeming.chen@epfl.ch);
(2) Gail Weiss, EPFL (antoine.bosselut@epfl.ch);
(3) Eric Mitchell, Stanford University (eric.mitchell@cs.stanford.edu)';
(4) Asli Celikyilmaz, Meta AI Research (aslic@meta.com);
(5) Antoine Bosselut, EPFL (antoine.bosselut@epfl.ch).
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\


You May Also Like

Stable Token Jumps 24.6% as Market Cap Crosses $771M: What’s Driving Volume?

Mastercard Launches Crypto Partnership Program with 85+ Firms


