

Bitcoin Hyper Presale Soars as Whales Buy In Early: Best Crypto Presale to Buy

Bitcoin may still wear the crown as crypto’s king, but it’s showing its age. Slow transactions, high fees, and limited use cases have left traders craving innovation.
This is where Bitcoin Hyper steps in, a new project redefining what Bitcoin can be in a world built for speed.
With more than $24 million raised in its presale, Bitcoin Hyper is drawing serious attention from whale wallets and retail investors. Many analysts already consider it one of the best crypto presales to buy as the market prepares for its next major rally.
By combining Bitcoin’s trusted security with Solana’s high-performance virtual machine, Bitcoin Hyper delivers near-instant transactions, low fees, and full support for DeFi and decentralized apps. It has the potential to reshape how Bitcoin is used heading into 2025.
Source – Cryptonews YouTube Channel
Bitcoin Hyper: The Layer 2 Solution Supercharging Bitcoin
At its core, Bitcoin Hyper tackles Bitcoin’s biggest limitation, speed. The main Bitcoin network processes around five transactions per second, while Solana handles roughly 800 on average, showcasing just how far behind Bitcoin’s base layer has fallen.
Bitcoin Hyper changes that completely by using the Solana Virtual Machine (SVM) and zero-knowledge proofs to bridge Bitcoin onto a fast, secure Layer 2 environment.

This allows sub-second transaction finality, minimal fees, and seamless scalability while keeping the original Bitcoin chain fully secure.
Developers can finally deploy DeFi platforms, staking protocols, and NFT marketplaces powered directly by Bitcoin, a capability that was never possible before. It’s a major technical leap that could redefine Bitcoin’s role in the Web3 economy.
How the Bridge Turns BTC into a Turbocharged Asset
The magic happens through Bitcoin Hyper’s canonical bridge. When users send BTC from the main chain, it’s verified and mirrored on Layer 2, allowing instant transfers, staking, and smart contract execution.
Every transaction batch is validated with zero-knowledge proofs and written back to Bitcoin’s base layer, ensuring that decentralization and trust remain intact.
This means users can send, trade, or participate in DeFi activities using their Bitcoin without waiting 10 minutes per block or paying high network fees. And when they’re done, assets can be moved back to the Bitcoin mainnet safely and transparently.
Beyond Transactions: Building a Complete Ecosystem
Bitcoin Hyper’s ambition extends beyond just faster payments. The project is developing an entire ecosystem that includes wallets, explorers, bridges, staking platforms, and developer tools.
Its tokenomics are built for sustainability; 30% of tokens are allocated for development, 25% for treasury, 20% for marketing, 15% for rewards, and 10% for listings.
This balanced allocation allows the team to fund long-term growth, innovation, and partnerships while rewarding early backers. The presale price of $0.01 per token initially drew massive whale participation, signaling strong market conviction in the project’s long-term potential.
Whales Are Leading the Accumulation
On-chain data confirms that large investors are steadily accumulating Bitcoin Hyper. Recent whale transactions include purchases of $379K, $274K, and $196K tokens, reflecting growing institutional confidence.
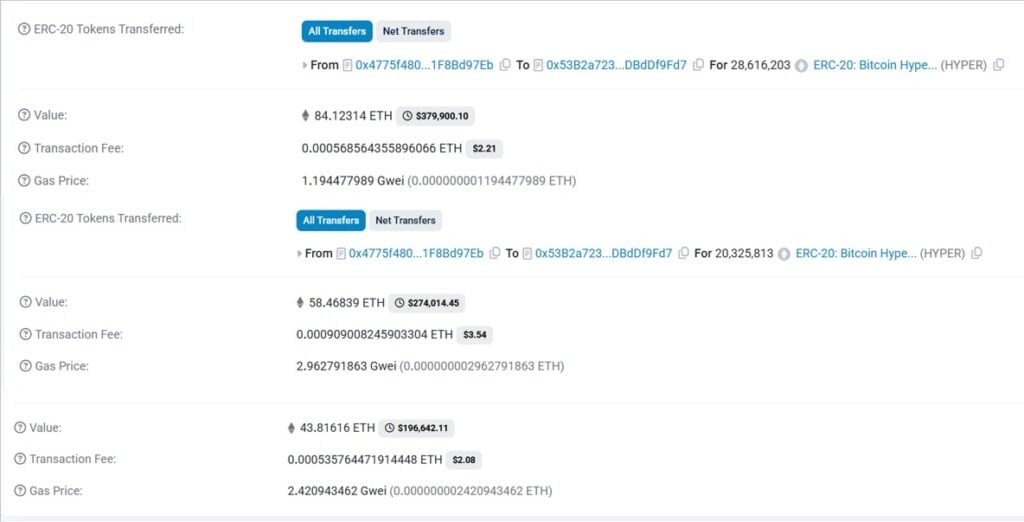
Many see Bitcoin Hyper as one of the best crypto presales to buy before its exchange listings go live.
With tokens now priced at $0.03125 and the presale entering its final stage, the window for early entry is narrowing fast.
For those positioning early for the next rally, Bitcoin Hyper combines real-world functionality with high growth potential, something few projects can deliver right now.
Whales Load Up on Bitcoin Hyper: The Fastest-Growing Crypto Presale of 2025
Early buyers don’t just receive tokens. They gain access to staking rewards of up to 50% APY, participate in governance decisions, and enjoy early entry into upcoming dApps within the Bitcoin Hyper ecosystem.
The Hyper token serves as the backbone of the network, powering everything from gas fees to DeFi utilities and forming the foundation for Bitcoin’s next phase of growth.
For investors exploring presales or managing their crypto holdings, Best Wallet offers a secure, non-custodial, KYC-free multi-chain solution available on the App Store and Google Play. It ensures safe participation in upcoming crypto presales while giving users full control of their assets and privacy.
With whale accumulation accelerating, Bitcoin Hyper has quickly become one of the fastest-growing presales in the market today, a project built not just for short-term hype but for the next major bull cycle and Bitcoin’s future evolution.
Visit Bitcoin Hyper
This article has been provided by one of our commercial partners and does not reflect Cryptonomist’s opinion. Please be aware our commercial partners may use affiliate programs to generate revenues through the links on this article.
You May Also Like

Tether Backs Ark Labs’ $5.2 Million Bet on Bitcoin’s Stablecoin Revival

Summarize Any Stock’s Earnings Call in Seconds Using FMP API
