

Establishing Verifiable Truth in a Post-Trust World
In an environment of perpetual digital noise, geopolitical friction, and algorithmic manipulation, many users have lost faith in the integrity of the information they see. The information landscape is saturated, blurring the lines between ordinary discourse and strategic misinformation by companies or states.
If high-stakes decisions (from investment strategies to international security choices) are based on data that can be fabricated or perpetually disputed, the global system will face a crisis of integrity and legitimacy.
One way to address this challenge is to have automated, neutral third-parties provide reliable information. In the world of Blockchains and Distributed Ledger Technology (DLT), this is called an Oracle, and the data it provided by Oracles can be codified in smart contracts. An Oracle’s job is to securely and automatically bridge external data into the immutable ledger. The Oracle acts as the objective, trustless witness: a key element in the trust required to enforce accountability and transparency across commerce, finance, and diplomacy, cutting through the noise, misinformation and disinformation that plagues the information landscape.
An Oracle can help answer questions that are key to trust: where do products come from? Who is trustworthy? And, are agreements - like geopolitical agreements - being upheld?
I. Traceability: Where Do Products Come From?
For consumers, regulators, and investors, proving the verifiable origin and journey of any product has become a strategic necessity.
Whether it is ensuring a luxury watch is not a counterfeit or confirming a shipment of rare earth minerals meets ethical sourcing requirements, the current system relies on paper trails and centralized, easily manipulable databases - not to mention some actors with incentives to cheat.
DLT provides the permanent ledger for these records. The Oracle provides the real-time link. Oracles can integrate sensor data, GPS coordinates, location analytics, and IoT data directly into the blockchain, creating a cryptographically secured timeline for a product’s lifecycle.
For example, when validating a critical component used in a fighter jet or confirming the quality of high-end agricultural exports, the Oracle pulls verified data from the physical world (time-stamped images of manufacturing facilities, atmospheric readings, or legal customs forms) and hashes it onto the DLT. This process ensures that both investors and regulators can confidently rely on the data’s integrity at every step. This application establishes a verifiable, tamper-proof layer of “ground truth”.
II. Who Is Trustworthy?
Investment decisions and lending practices are, essentially, risk assessments based on expected performance. When an enterprise, particularly in an illiquid sector like commercial real estate or specialized manufacturing, claims strong activity, that claim must be verifiable.
This is where the Oracle enables external, objective validation against fraudulent financial reporting. If a business claims massive operational output, an Oracle can be programmed to integrate objective data streams that reflect that activity.
For example, the claims a physical business is making about substantial activity can be supported by satellite or aerial imagery showing traffic density, vehicle types, or parking lot occupancy over time. This data can serve an important purpose in auditing commercial claims. Regulators, shareholders, and potential acquirers can use it to validate financial integrity, providing transparency to a market often obscured by selective reporting.
III. Are Agreements Being Upheld?
The highest stakes for verification lie in geopolitical competition, where strategic rivalry often overrides political consensus. Nations frequently accuse one another of violating sanctions, ceasefires, or non-proliferation agreements, such as allegations regarding illicit oil trade or nuclear enrichment levels. This prolongs conflicts due to conflicting intelligence and propaganda, serving narrow political goals. It also reduces business confidence.
Here, too, automated Oracles offer a mechanism to enforce necessary transparency when political trust is absent. For sensitive geopolitical concerns, automated verification can bring added value by acting as a shared data management system where multiple parties lack a central trusted third party.
For example, When tackling sophisticated evasion techniques, such as the use of “shadow fleets” to conceal illicit maritime trade, an Oracle can integrate vast streams of data, including satellite maritime tracking, vessel registration changes, and known association networks.
Conclusion
Whether securing a supply chain, verifying corporate claims, or stabilizing global security, the combination of DLT's immutable record and the Oracle's automated, neutral testimony is the necessary architecture for restoring a measure of verifiable ground truth in our digital age.
You May Also Like

The Stunning ASEAN Winner Emerges As Manufacturing Shifts Accelerate
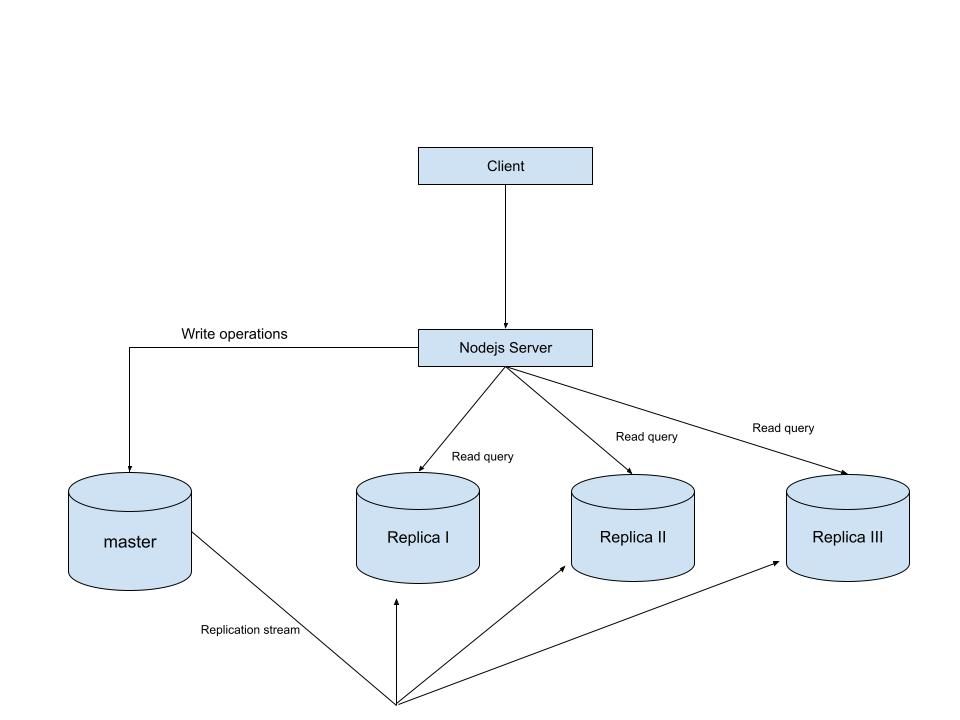
MySQL Single Leader Replication with Node.js and Docker
command: --server-id=1 --log-bin=ON The --server-id option gives each MySQL server in your replication setup its own name tag. Each one has to be unique and without it, replication won’t work at all. Another cool option not included here is binlog_format=ROW. This tells MySQL how to keep track of changes before passing them along to the replicas. By default, MySQL already uses row-based replication, but you can explicitly set it to ROW to be sure or switch it to STATEMENT if you’d rather log the actual SQL statements instead of row-by-row changes. \ Run our containers on docker Now, in the terminal, we can run the following command to spin up our database containers: docker-compose up -d \ Setting Up Our Master (Primary) Server To configure our master server, we would have to first access the running instance on docker using the following command docker exec -it mysql-master bash This command opens an interactive Bash shell inside the running Docker container named mysql-master, allowing us to run commands directly inside that container. \ Now that we’re inside the container, we can access the MySQL server and start running commands. type: mysql -uroot -p This will log you into MySQL as the root user. You’ll be prompted to enter the password you set in your docker-compose.yml file. \ Next, we need to create a special user that our replicas will use to connect to the master server and pull data. Inside the MySQL prompt, run the following commands: \ CREATE USER 'repl_user'@'%' IDENTIFIED BY 'replication_pass'; GRANT REPLICATION SLAVE ON . TO 'repl_user'@'%'; FLUSH PRIVILEGES; Here’s what’s happening: CREATE USER makes a new MySQL user called repl_user with the password replication_pass. GRANT REPLICATION SLAVE gives this user permission to act as a replication client. FLUSH PRIVILEGES tells MySQL to reload the user permissions so they take effect immediately. \ Time to Configure the Replica (Secondary) Servers a. First, let’s access the replica containers the same way we did with the master. Run this command in your terminal for each of the replica containers: \ docker exec -it <replica_container_name> bash mysql -uroot -p <replica_container_name> should be replace with the name of the replica container you are trying to setup b. Now it’s time to tell our replica where to get its data from. While inside the replica’s MySQL shell, run the following command to configure replication using the master’s details: CHANGE REPLICATION SOURCE TO SOURCE_HOST='mysql-master', SOURCE_USER='repl_user', SOURCE_PASSWORD='replication_pass', GET_SOURCE_PUBLIC_KEY=1; With the replication settings in place, let’s fire up the replica and get it syncing with the master. Still inside the MySQL shell on the replica, run: START REPLICA; This starts the replication process. To make sure everything is working, check the replica’s status with:
SHOW REPLICA STATUS\G; Look for Replica_IO_Running and Replica_SQL_Running — if both say Yes, congratulations! 🎉 Your replica is now successfully connected to the master and replicating data in real time.
Testing Our Replication Setup from the Node.js App Now that our replication is successfully set up, we can configure our Node.js server to observe the real-time effect of data being replicated from the master server to the replica server whenever we write to it. We start by installing the following dependencies:
npm i express mysql2 sequelize \ Now create a folder called src in the root directory and add the following files inside that folder connection.js, index.js and model.js. Our current directory should look like this We can now set up our connections to our master and replica server in the connection.js file as shown below
const Sequelize = require("sequelize"); const sequelize = new Sequelize({ dialect: "mysql", replication: { write: { host: "127.0.0.1", username: "root", password: "master", database: "replicaDb", }, read: [ { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3307 }, { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3308 }, { host: "127.0.0.1", username: "root", password: "slave", database: "replicaDb", port: 3309 }, ], }, }); async function connectdb() { try { await sequelize.authenticate(); } catch (error) { console.error("❌ unable to connect to the follower database", error); } } connectdb(); module.exports = { sequelize, }; \ We can now create a User table in the model.js file
const {DataTypes} = require("sequelize"); const { sequelize } = require("./connection"); const User = sequelize.define("User", { name: { type: DataTypes.STRING, allowNull: false, }, email: { type: DataTypes.STRING, unique: true, allowNull: false, }, }); module.exports = User \ and finally in our index.js file we can start our server and listen for connections on port 3000. from the code sample below, all inserts or updates will be routed by sequelize to the master server. while all read queries will be routed to the read replicas.
const express = require("express"); const { sequelize } = require("./connection"); const User = require("./model"); const app = express(); app.use(express.json()); async function main() { await sequelize.sync({ alter: true }); app.get("/", (req, res) => { res.status(200).json({ message: "first step to setting server up", }); }); app.post("/user", async (req, res) => { const { email, name } = req.body; let newUser = await User.build({ name, email, }); // This INSERT will go to the write (master) connection newUser = newUser.save({ returning: false }); res.status(201).json({ message: "User successfully created", }); }); app.get("/user", async (req, res) => { // This SELECT query will go to one of the read replicas const users = await User.findAll(); res.status(200).json(users); }); app.listen(3000, () => { console.log("server has connected"); }); } main(); When you make a POST request to the /users endpoint, take a moment to check both the master and replica servers to observe how data is replicated in real time. Right now, we are relying on Sequelize to automatically route requests, which works for development but isn’t robust enough for a production environment. In particular, if the master node goes down, Sequelize cannot automatically redirect requests to a newly elected leader. In the next part of this series, we’ll explore strategies to handle these challenges
