

Performanța Optimizării pe Încorporări Gaussian și Arbore Sintetice
Tabel de Linkuri
Rezumat și 1. Introducere
-
Lucrări Corelate
-
Tehnici de Relaxare Convexă pentru SVM Hiperbolice
3.1 Preliminarii
3.2 Formularea Originală a HSVM
3.3 Formulare Semidefinită
3.4 Relaxare Moment-Sumă-de-Pătrate
-
Experimente
4.1 Set de Date Sintetic
4.2 Set de Date Real
-
Discuții, Mulțumiri și Referințe
\
A. Demonstrații
B. Extragerea Soluției în Formularea Relaxată
C. Despre Ierarhia de Relaxare Moment Sumă-de-Pătrate
D. Scalare Platt [31]
E. Rezultate Experimentale Detaliate
F. Mașină cu Vectori de Suport Hiperbolică Robustă
4.1 Set de Date Sintetic
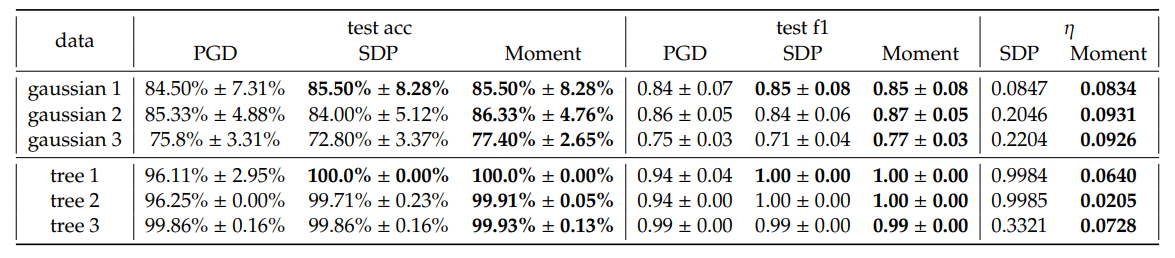
\ În general, observăm un câștig mic în acuratețea medie de testare și scorul F1 ponderat de la SDP și Moment în raport cu PGD. Este de remarcat faptul că Moment arată adesea îmbunătățiri mai consistente în comparație cu SDP, pe majoritatea configurațiilor. În plus, Moment oferă goluri de optimalitate 𝜂 mai mici decât SDP. Acest lucru corespunde așteptării noastre că Moment este mai strâns decât SDP.
\ Deși în unele cazuri, de exemplu când 𝐾 = 5, Moment obține pierderi semnificativ mai mici în comparație cu atât PGD, cât și SDP, nu este în general cazul. Subliniem că aceste pierderi nu sunt măsurători directe ale generalizabilității separatoarelor hiperbolice cu marjă maximă; mai degrabă, sunt combinații de maximizare a marjei și penalizare pentru clasificare greșită care scalează cu 𝐶. Prin urmare, observația că performanța în acuratețea de testare și scorul F1 ponderat este mai bună, chiar dacă pierderea calculată folosind soluții extrase din SDP și Moment este uneori mai mare decât cea de la PGD, ar putea fi datorată peisajului complicat al pierderii. Mai specific, creșterile observate în pierdere pot fi atribuite complexităților peisajului mai degrabă decât eficacității metodelor de optimizare. Pe baza rezultatelor de acuratețe și scor F1, empiric metodele SDP și Moment identifică soluții care generalizează mai bine decât cele obținute prin rularea doar a coborârii gradientului. Oferim o analiză mai detaliată asupra efectului hiperparametrilor în Anexa E.2 și timpul de execuție în Tabelul 4. Granița de decizie pentru Gaussian 1 este vizualizată în Figura 5.
\ ![Figura 3: Trei Gaussiene Sintetice (rândul de sus) și Trei Încorporări de Arbore (rândul de jos). Toate caracteristicile sunt în H2, dar vizualizate prin proiecție stereografică pe B2. Culori diferite reprezintă clase diferite. Pentru setul de date arbore, conexiunile grafului sunt, de asemenea, vizualizate, dar nu sunt utilizate în antrenament. Încorporările de arbore selectate provin direct de la Mishne și colab. [6].](https://cdn.hackernoon.com/images/null-yv132j7.png)
\ Încorporare Sintetică de Arbore. Deoarece spațiile hiperbolice sunt bune pentru încorporarea arborilor, generăm grafuri de arbori aleatorii și le încorporăm în H2 urmând Mishne și colab. [6]. Specific, etichetăm nodurile ca pozitive dacă sunt copii ai unui nod specificat și negative în caz contrar. Modelele noastre sunt apoi evaluate pentru clasificarea subarborelui, având ca scop identificarea unei limite care include toate nodurile copil din același subarbore. O astfel de sarcină are diverse aplicații practice. De exemplu, dacă arborele reprezintă un set de token-uri, granița de decizie poate evidenția regiuni semantice în spațiul hiperbolic care corespund subarborilor grafului de date. Subliniem că o caracteristică comună în astfel de sarcini de clasificare a subarborilor este dezechilibrul de date, care de obicei duce la generalizabilitate slabă. Prin urmare, ne propunem să folosim această sarcină pentru a evalua performanțele metodelor noastre în acest cadru provocator. Trei încorporări sunt selectate și vizualizate în Figura 3, iar performanța este rezumată în Tabelul 1. Timpul de execuție al arborilor selectați poate fi găsit în Tabelul 4. Granița de decizie a arborelui 2 este vizualizată în Figura 6.
\ Similar cu rezultatele seturilor de date Gaussiene sintetice, observăm performanțe mai bune de la SDP și Moment în comparație cu PGD, iar datorită dezechilibrului de date cu care metodele GD se luptă de obicei, avem un câștig mai mare în scorul F1 ponderat în acest caz. În plus, observăm goluri mari de optimalitate pentru SDP, dar gol foarte strâns pentru Moment, certificând optimalitatea lui Moment chiar și atunci când dezechilibrul de clasă este sever.
\ 
\
:::info Autori:
(1) Sheng Yang, John A. Paulson School of Engineering and Applied Sciences, Harvard University, Cambridge, MA (shengyang@g.harvard.edu);
(2) Peihan Liu, John A. Paulson School of Engineering and Applied Sciences, Harvard University, Cambridge, MA (peihanliu@fas.harvard.edu);
(3) Cengiz Pehlevan, John A. Paulson School of Engineering and Applied Sciences, Harvard University, Cambridge, MA, Center for Brain Science, Harvard University, Cambridge, MA, și Kempner Institute for the Study of Natural and Artificial Intelligence, Harvard University, Cambridge, MA (cpehlevan@seas.harvard.edu).
:::
:::info Această lucrare este disponibilă pe arxiv sub licență CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International).
:::
\


Poate îți place și

Iată 7 motive pentru care Legea CLARITY ar putea să nu devină lege

Juriul decide împotriva lui Elon Musk în procesul OpenAI, deschizând calea pentru IPO




