

Optimización de Costo y Utilización de Clúster de Databricks Sin Tablas del Sistema

En la mayoría de los entornos empresariales de Databricks (como en MSC o grandes ecosistemas de analítica), las tablas del sistema como system.jobrunlogs o system.cluster_events pueden estar restringidas o deshabilitadas debido a políticas de seguridad o gobernanza.
Sin embargo, el seguimiento de la utilización y costo del clúster es crucial para:
- Comprender cómo los trabajos utilizan eficientemente el cómputo
- Identificar clústeres inactivos o fugas de costos
- Pronosticar el presupuesto de infraestructura
- Construir paneles de costos personalizados
Este blog demuestra un enfoque paso a paso para calcular la utilización y costo del clúster utilizando solo APIs REST de Databricks — sin necesidad de tablas del sistema.
Caso de Uso del Proyecto
En nuestra plataforma de datos MSC, ejecutamos múltiples clústeres de Databricks en desarrollo, pruebas y producción. \n Tuvimos tres desafíos principales:
- Sin acceso a tablas del sistema (restringido por políticas administrativas)
- Clústeres efímeros para trabajos creados dinámicamente por ADF o pipelines de orquestación
- Sin vista directa de cómo la utilización del clúster se traduce en costo
Por lo tanto, construimos un analizador de utilización ligero que:
- Extrae datos de las APIs REST de Databricks
- Calcula el tiempo de ejecución del trabajo vs el tiempo de ejecución del clúster
- Estima el costo utilizando tasas de DBU y VM
- Genera un DataFrame fácil de consumir
El problema y enfoque
El desafío identificado
Los equipos a menudo necesitan saber:
- ¿Qué clústeres están inactivos (ejecutándose con poca actividad de trabajos)?
- ¿Cuál es el % de utilización (tiempo de ejecución del trabajo vs tiempo de actividad del clúster)?
- ¿Cuánto cuesta cada clúster (DBU + VM)?
Cuando las tablas del sistema de Unity Catalog (por ejemplo, system.jobrunlogs) no están disponibles, el enfoque predeterminado basado en SQL falla. La API REST se convierte en la alternativa confiable.
Enfoque de alto nivel utilizado en el notebook
- Listar clústeres a través de /api/2.0/clusters/list.
- Estimar el tiempo de actividad del clúster usando marcas de tiempo dentro del JSON del clúster (campos created/start/terminated). (Esta es una alternativa pragmática cuando /clusters/events no está disponible.)
- Obtener ejecuciones recientes de trabajos usando /api/2.1/jobs/runs/list con filtros de tiempo (o límite).
- Hacer coincidir ejecuciones de trabajos con clústeres usando clusterinstance.clusterid (u otros metadatos del clúster).
- Calcular utilización: % de utilización = totaljobruntime / totalclusteruptime.
- Estimar costo usando una fórmula simple: costo = runninghours × (DBU/hr × DBU asumido) + runninghours × nodes × VM $/hr.
Este notebook utiliza intencionalmente consultas acotadas (últimas N ejecuciones, ventana de tiempo) para que se ejecute rápidamente.
\ 1. Configuración e Instalación
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Esta sección inicializa:
- URL del espacio de trabajo y token para autenticación
- Rango de tiempo para el cual desea analizar la utilización
- Supuestos de costo:
- Tasa de DBU ($/hr por DBU)
- Costo del nodo VM
- Consumo aproximado de DBU
En configuraciones empresariales, estas tasas se pueden obtener dinámicamente a través de sus APIs de FinOps o facturación.
-
Función Contenedora de API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Esta función auxiliar estandariza todas las llamadas GET de la API REST. \n Esta:
-
Construye la URL completa del endpoint
-
Maneja 404 de manera elegante (importante cuando los clústeres o ejecuciones han expirado)
-
Devuelve JSON analizado
Por qué es importante: Esta función garantiza una comunicación limpia con la API sin interrumpir el flujo de su notebook si falta algún dato del clúster.
\
-
Listar Todos los Clústeres Activos
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ Esto recupera todos los clústeres disponibles en su espacio de trabajo. \n Es equivalente a ver su pestaña "Compute" de forma programática. \n La respuesta contiene:
-
IDs de clúster
-
Nombres
-
Conteo de nodos
-
Información del creador
-
Tiempos de creación y terminación
Caso de uso: Ayuda a identificar qué clústeres están consumiendo recursos en la ventana seleccionada.
4. Estimar Tiempo de Ejecución del Clúster
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Calculamos las horas totales de ejecución para cada clúster:
-
Utiliza marcas de tiempo de creación y terminación
-
Maneja clústeres actualmente en ejecución (terminated_time faltante)
-
Normaliza a horas
Por qué es importante: Este valor es el denominador para la utilización — representando el tiempo total de actividad del clúster durante la ventana.
5. Obtener Ejecuciones Recientes de Trabajos
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ En lugar de obtener todo el historial de trabajos (que es lento), \n Esta función recupera las 10 ejecuciones de trabajos más recientes para diagnósticos rápidos.
En producción, puede filtrar por:
- job_id específico
- completed_only=true
- Ventana de fecha (starttimefrom, starttimeto)
\
-
Calcular Utilización y Costo
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
Este es el corazón de la lógica:
-
Recorre cada clúster
-
Calcula el tiempo de ejecución del trabajo total por clúster (usando la API de ejecuciones de trabajos)
-
Deriva el porcentaje de utilización = (jobhours / clusterrunning_hours) × 100
-
Estima el costo:
- Costo de DBU basado en tasa × DBU/hr
- Costo de VM = nodecount × nodecost/hr × running_hours
Por qué es importante: \n Esto proporciona una imagen unificada de eficiencia y gasto — útil para identificar clústeres con alto costo pero baja utilización.
7. Orquestar el Pipeline
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Este bloque final:
-
Recupera datos
-
Realiza el cálculo de costos
-
Muestra el DataFrame ordenado
En la práctica, este DataFrame puede ser:
-
Exportado a Excel o Delta Table
-
Enviado a paneles de Power BI
-
Integrado en pipelines de automatización de FinOps
\
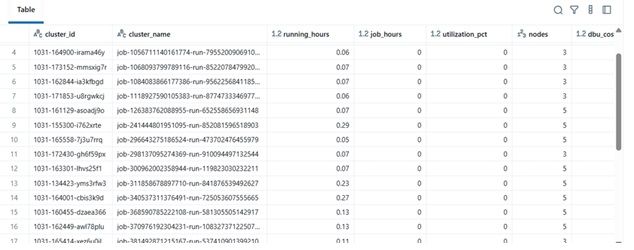
Ejemplo de Resultados
| clustername | runninghours | jobhours | utilizationpct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
Beneficio en el Mundo Real
Al implementar este analizador:
-
Los equipos de ingeniería pueden rastrear el costo del clúster incluso sin acceso de auditoría.
-
Los gerentes obtienen visibilidad sobre clústeres subutilizados.
-
DevOps puede terminar automáticamente clústeres de bajo uso.
-
Finanzas puede validar facturas de Databricks con métricas internas.
En nuestro proyecto MSC, utilizamos esto como parte de nuestro stack de observabilidad de la plataforma de datos — combinando datos de la API REST, registros de trabajos de ADF y tendencias de costos en un panel unificado.
\


También te puede interesar

Predicción de Precio de Bittensor – Se Estima que el Precio de TAO Caiga a $ 202.28 el 23 de Mayo de 2026

xAI integra Grok con el Agente Hermes, alcanzando a más de 130,000 usuarios al instante




