

Cómo Toto Reimagina la Atención Multi-Cabezal para la Previsión Multivariante

Tabla de Enlaces
- Antecedentes
- Planteamiento del problema
- Arquitectura del modelo
- Datos de entrenamiento
- Resultados
- Conclusiones
- Declaración de impacto
- Direcciones futuras
- Contribuciones
- Agradecimientos y Referencias
Apéndice
3 Arquitectura del modelo
Toto es un modelo de pronóstico basado únicamente en decodificador. Este modelo emplea muchas de las técnicas más recientes de la literatura, e introduce un método novedoso para adaptar la atención multi-cabezal a datos de series temporales multivariantes (Fig. 1).
\ 3.1 Diseño del Transformer
\ Los modelos Transformer para pronóstico de series temporales han utilizado diversas arquitecturas: codificador-decodificador [12, 13, 21], solo codificador [14, 15, 17], y solo decodificador [19, 23]. Para Toto, empleamos una arquitectura de solo decodificador. Se ha demostrado que las arquitecturas de decodificador escalan bien [25, 26], y permiten horizontes de predicción arbitrarios. La tarea causal de predicción del siguiente parche también simplifica el proceso de pre-entrenamiento.
\ Utilizamos técnicas de algunas de las arquitecturas más recientes de modelos de lenguaje grande (LLM), incluyendo pre-normalización [27], RMSNorm [28], y capas feed-forward SwiGLU [29].
\ 3.2 Incrustación de entrada
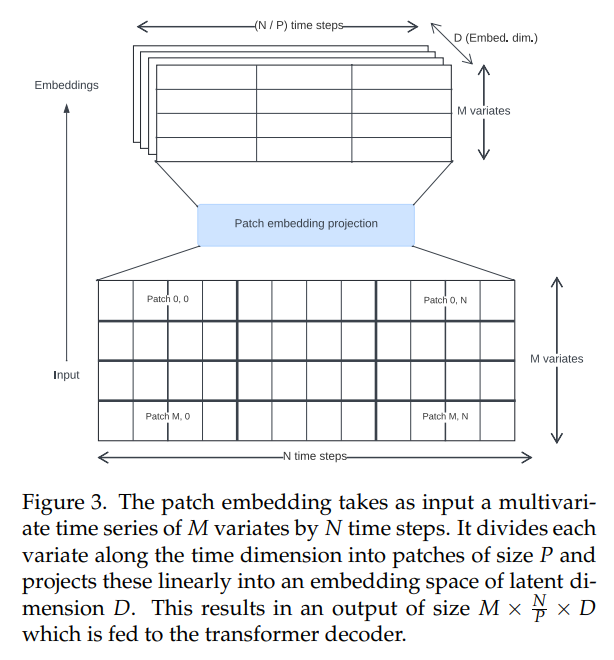
\ Los transformers de series temporales en la literatura han utilizado varios enfoques para crear incrustaciones de entrada. Utilizamos proyecciones de parches no superpuestos (Fig. 3), introducidas por primera vez para Vision Transformers [30, 31] y popularizadas en el contexto de series temporales por PatchTST [14]. Toto fue entrenado utilizando un tamaño de parche fijo de 32.
\ 
\ 3.3 Mecanismo de atención
\ Las métricas de observabilidad son a menudo series temporales multivariantes de alta cardinalidad. Por lo tanto, un modelo ideal manejará de forma nativa el pronóstico multivariante. Debe ser capaz de analizar relaciones tanto en la dimensión temporal (lo que denominamos interacciones "time-wise") como en la dimensión de canal (lo que denominamos interacciones "space-wise", siguiendo la convención en la plataforma Datadog de describir diferentes grupos o conjuntos de etiquetas de una métrica como la dimensión "espacio").
\ Para modelar interacciones tanto espaciales como temporales, necesitamos adaptar la arquitectura tradicional de atención multi-cabezal [11] de una a dos dimensiones. Se han propuesto varios enfoques en la literatura para hacer esto, incluyendo:
\ • Asumir independencia de canal, y calcular la atención solo en la dimensión temporal [14]. Esto es eficiente, pero descarta toda la información sobre interacciones espaciales.
\ • Calcular la atención solo en la dimensión espacial, y utilizar una red feed-forward en la dimensión temporal [17, 18].
\ • Concatenar variantes a lo largo de la dimensión temporal y calcular atención cruzada completa entre cada ubicación espacio/tiempo [15]. Esto puede capturar todas las posibles interacciones de espacio y tiempo, pero es computacionalmente costoso.
\ • Calcular "atención factorizada", donde cada bloque transformer contiene un cálculo de atención separado para espacio y tiempo [16, 32, 33]. Esto permite la mezcla tanto espacial como temporal, y es más eficiente que la atención cruzada completa. Sin embargo, duplica la profundidad efectiva de la red.
\ Para diseñar nuestro mecanismo de atención, seguimos la intuición de que para muchas series temporales, las relaciones temporales son más importantes o predictivas que las relaciones espaciales. Como evidencia, observamos que incluso los modelos que ignoran completamente las relaciones espaciales (como PatchTST [14] y TimesFM [19]) aún pueden lograr un rendimiento competitivo en conjuntos de datos multivariantes. Sin embargo, otros estudios (por ejemplo, Moirai [15]) han demostrado mediante ablaciones que hay un claro beneficio al incluir relaciones espaciales.
\ Por lo tanto, proponemos una nueva variante de atención factorizada, que llamamos "Atención Espacio-Temporal Factorizada Proporcional". Utilizamos una mezcla de bloques de atención espacial y temporal alternados. Como hiperparámetro configurable, podemos cambiar la proporción de bloques temporales a espaciales, permitiéndonos dedicar más o menos presupuesto computacional a cada tipo de atención. Para nuestro modelo base, seleccionamos una configuración con un bloque de atención espacial por cada dos bloques temporales.
\ En los bloques de atención temporal, utilizamos enmascaramiento causal e incrustaciones posicionales rotatorias [34] con XPOS [35] para modelar autorregresivamente características dependientes del tiempo. En los bloques espaciales, por el contrario, utilizamos atención bidireccional completa para preservar la invariancia de permutación de las covariables, con una máscara de ID en bloque diagonal para garantizar que solo las variantes relacionadas presten atención entre sí. Este enmascaramiento nos permite empaquetar múltiples series temporales multivariantes independientes en el mismo lote, para mejorar la eficiencia del entrenamiento y reducir la cantidad de relleno.
\ 3.4 Cabeza de predicción probabilística
\ Para ser útil en aplicaciones de pronóstico, un modelo debe producir predicciones probabilísticas. Una práctica común en modelos de series temporales es utilizar una capa de salida donde el modelo regresa los parámetros de una distribución de probabilidad. Esto permite calcular intervalos de predicción utilizando muestreo de Monte Carlo [7].
\ Las opciones comunes para una capa de salida son Normal [7] y Student-T [23, 36], que pueden mejorar la robustez frente a valores atípicos. Moirai [15] permite distribuciones residuales más flexibles al proponer un nuevo modelo de mezcla que incorpora una combinación ponderada de salidas Gaussianas, Student-T, Log-Normal y Binomial Negativa.
\ Sin embargo, las series temporales del mundo real a menudo tienen distribuciones complejas difíciles de ajustar, con valores atípicos, colas pesadas, asimetría extrema y multimodalidad. Para acomodar estos escenarios, introducimos una verosimilitud de salida aún más flexible. Para hacer esto, empleamos un método basado en modelos de mezcla Gaussiana (GMMs), que pueden aproximar cualquier función de densidad ([37]). Para evitar la inestabilidad del entrenamiento en presencia de valores atípicos, utilizamos un modelo de mezcla Student-T (SMM), una generalización robusta de GMMs [38] que ha mostrado promesa previamente para modelar series temporales financieras de cola pesada [39, 40]. El modelo predice k distribuciones Student-T (donde k es un hiperparámetro) para cada paso de tiempo, así como una ponderación aprendida.
\ 
\ Cuando realizamos inferencia, extraemos muestras de la distribución de mezcla en cada marca de tiempo, luego alimentamos cada muestra de vuelta al decodificador para la siguiente predicción. Esto nos permite producir intervalos de predicción en cualquier cuantil, limitados solo por el número de muestras; para colas más precisas, podemos elegir gastar más cómputo en el muestreo (Fig. 2).
\ 3.5 Escalado de entrada/salida
\ Como en otros modelos de series temporales, realizamos normalización de instancia en los datos de entrada antes de pasarlos por la incrustación de parche, para hacer que el modelo generalice mejor a entradas de diferentes escalas [41]. Escalamos las entradas para que tengan media cero y desviación estándar unitaria. Las predicciones de salida luego se reescalan de vuelta a las unidades originales.
\ 3.6 Objetivo de entrenamiento
\ Como modelo de solo decodificador, Toto es pre-entrenado en la tarea de predicción del siguiente parche. Minimizamos la log-verosimilitud negativa del siguiente parche predicho con respecto a la salida de distribución del modelo. Entrenamos el modelo utilizando el optimizador AdamW [42].
\ 3.7 Hiperparámetros
\ Los hiperparámetros utilizados para Toto se detallan en la Tabla A.1, con un total de 103 millones de parámetros.
\
:::info Autores:
(1) Ben Cohen (ben.cohen@datadoghq.com);
(2) Emaad Khwaja (emaad@datadoghq.com);
(3) Kan Wang (kan.wang@datadoghq.com);
(4) Charles Masson (charles.masson@datadoghq.com);
(5) Elise Rame (elise.rame@datadoghq.com);
(6) Youssef Doubli (youssef.doubli@datadoghq.com);
(7) Othmane Abou-Amal (othmane@datadoghq.com).
:::
:::info Este artículo está disponible en arxiv bajo licencia CC BY 4.0.
:::
\


También te puede interesar

Actualización del Protocolo Pi Network v24 Indica el Desarrollo Continuo del Ecosistema

Apyx profundiza su apuesta en MicroStrategy con una posición en acciones preferentes de 280 millones de dólares




