

OpenAI observa una mejora del 30% en la equidad de ChatGPT
TLDRs;
- OpenAI afirma una reducción del 30% en el sesgo político de ChatGPT, citando evaluaciones internas que utilizan 500 prompts en 100 temas.
- Los críticos argumentan que los hallazgos carecen de verificación independiente, ya que OpenAI no ha publicado su metodología completa ni sus conjuntos de datos.
- La Ley de IA de la UE exige la detección de sesgos y auditorías de terceros para sistemas de IA de alto riesgo, aumentando la presión de cumplimiento sobre OpenAI.
- A pesar del progreso, la neutralidad política en modelos grandes sigue sin resolverse, ya que las interpretaciones de "justicia" difieren entre las audiencias.
OpenAI ha revelado una nueva investigación interna que muestra que sus últimas versiones de ChatGPT (GPT-5 instant y GPT-5 thinking) demuestran una mejora del 30% en justicia al manejar temas políticamente cargados o ideológicamente sensibles.
Según la empresa, la evaluación involucró 500 prompts que cubren 100 temas políticos diferentes, utilizando un marco estructurado diseñado para detectar cinco tipos de sesgo. Estos incluían opiniones personales, encuadres unilaterales y respuestas emocionalmente cargadas. Los hallazgos de OpenAI sugieren que menos del 0,01% de los resultados de ChatGPT en el mundo real muestran algún sesgo político medible, basado en el tráfico de millones de interacciones de usuarios.
La empresa declaró que estos resultados reflejan su misión en curso de hacer que los sistemas de IA sean más neutrales y confiables, particularmente en conversaciones que involucran política, medios y identidad social.
El Marco Todavía Carece de Verificación Independiente
Mientras que el anuncio señala progreso, los expertos han expresado preocupaciones sobre la falta de reproducibilidad en las afirmaciones de justicia de OpenAI.
La empresa no ha compartido el conjunto de datos completo, la rúbrica de evaluación o los prompts específicos utilizados en sus pruebas internas, dejando a los investigadores independientes incapaces de verificar si la caída del 30% refleja una verdadera neutralidad o simplemente una ingeniería de prompts optimizada que oculta el sesgo bajo condiciones controladas.
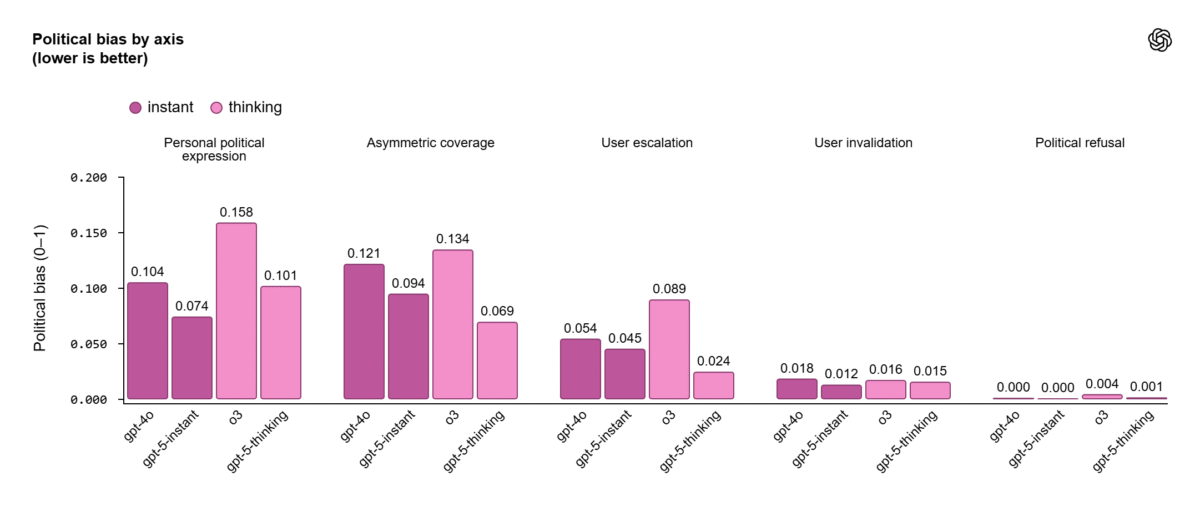 GPT‑5 instant y thinking superan a GPT‑4o y o3 en todos los ejes medidos.
GPT‑5 instant y thinking superan a GPT‑4o y o3 en todos los ejes medidos.
Un estudio de la Universidad de Stanford a principios de este año probó 24 modelos de lenguaje de ocho empresas, puntuándolos usando más de 10.000 calificaciones públicas. Los hallazgos sugirieron que los modelos anteriores de OpenAI mostraban una inclinación política percibida más fuerte en comparación con competidores como Google, con usuarios de todo el espectro político de EE.UU. interpretando las mismas respuestas de manera diferente según sus tendencias ideológicas.
El debate subraya la complejidad de medir el sesgo político en modelos generativos, donde incluso una formulación neutral puede ser interpretada como partidista dependiendo del contexto, la cultura o la formulación.
Las Reglas de la UE Impulsan Auditorías Externas de Sesgo
Los hallazgos llegan mientras la Ley de IA de Europa comienza a establecer nuevos estándares de responsabilidad. Bajo el Artículo 10, los modelos de IA de alto riesgo y de propósito general (GPAI) deben detectar, reducir y documentar el sesgo.
Los sistemas que excedan 10²⁵ operaciones de punto flotante (FLOPs), un indicador de poder computacional masivo, también deben realizar evaluaciones de riesgo sistémico, informar incidentes de seguridad y documentar procedimientos de gobernanza de datos. El incumplimiento podría llevar a multas de hasta €35 millones o el 7% de la facturación global.
Los auditores independientes pronto jugarán un papel importante en la verificación de la justicia de los modelos de IA, proporcionando monitoreo continuo utilizando evaluaciones basadas tanto en humanos como en IA. La Comisión Europea emitirá Códigos de Práctica para abril de 2025, ofreciendo orientación detallada sobre cómo los proveedores de GPAI como OpenAI pueden demostrar cumplimiento.
Equilibrando el Progreso con la Responsabilidad
A pesar de su optimismo interno, OpenAI permanece bajo creciente escrutinio de reguladores y académicos por igual. La empresa ha reconocido que el sesgo político e ideológico sigue siendo un problema de investigación abierto, que requiere refinamiento a largo plazo en la recopilación de datos, etiquetado y técnicas de aprendizaje por refuerzo.
En paralelo, OpenAI se reunió recientemente con reguladores antimonopolio de la UE, planteando preocupaciones de competencia sobre el dominio de las principales empresas tecnológicas, particularmente Google, en el espacio de IA. Con más de 800 millones de usuarios semanales de ChatGPT y una valoración que supera los US$500 mil millones, OpenAI ahora se encuentra en la intersección de la innovación y la tensión regulatoria.
La publicación OpenAI ve una mejora del 30% en la justicia de ChatGPT apareció primero en CoinCentral.


También te puede interesar

Exclusiva: PayPal cierra su rama de capital de riesgo mientras el gigante fintech se reestructura bajo su nuevo CEO

'Sin amigos': Internet se burla de Trump por la vergonzosa foto del G7

El recompra de $0.10 de BlockDAG supera la marca de 1B monedas mientras XRP se expande con pagos de IA de Mastercard y AVAX llega a Nasdaq



