

Solution à la rareté des données : S-CycleGAN pour la traduction de CT en échographie
Table des liens
Abstrait et 1 Introduction
-
Travaux connexes
-
Définition du problème
-
Méthodologie
4.1. Distillation consciente des limites de décision
4.2. Consolidation des connaissances
-
Résultats expérimentaux et 5.1. Configuration de l'expérience
5.2. Comparaison avec les méthodes de pointe
5.3. Étude d'ablation
-
Conclusion et travaux futurs et Références
\
Matériel supplémentaire
- Détails de l'analyse théorique du mécanisme KCEMA dans l'IIL
- Aperçu de l'algorithme
- Détails des ensembles de données
- Détails d'implémentation
- Visualisation des images d'entrée poussiéreuses
- Plus de résultats expérimentaux
Abstrait
L'apprentissage incrémental par instance (IIL) se concentre sur l'apprentissage continu avec des données des mêmes classes. Comparé à l'apprentissage incrémental par classe (CIL), l'IIL est rarement exploré car l'IIL souffre moins de l'oubli catastrophique (CF). Cependant, outre la conservation des connaissances, dans les scénarios de déploiement réels où l'espace des classes est toujours prédéfini, la promotion continue et rentable du modèle avec l'indisponibilité potentielle des données précédentes est une demande plus essentielle. Par conséquent, nous définissons d'abord un nouveau paramètre IIL plus pratique comme promouvoir les performances du modèle en plus de résister au CF avec seulement de nouvelles observations. Deux problèmes doivent être abordés dans le nouveau cadre IIL : 1) l'oubli catastrophique notoire en raison de l'absence d'accès aux anciennes données, et 2) l'élargissement de la limite de décision existante aux nouvelles observations en raison de la dérive conceptuelle. Pour résoudre ces problèmes, notre idée clé est d'élargir modérément la limite de décision aux cas d'échec tout en conservant l'ancienne limite. Par conséquent, nous proposons une nouvelle méthode de distillation consciente des limites de décision avec consolidation des connaissances vers l'enseignant pour faciliter l'apprentissage de nouvelles connaissances par l'étudiant. Nous établissons également les références sur les ensembles de données existants Cifar-100 et ImageNet. Notamment, des expériences approfondies démontrent que le modèle enseignant peut être un meilleur apprenant incrémental que le modèle étudiant, ce qui renverse les méthodes précédentes basées sur la distillation des connaissances traitant l'étudiant comme le rôle principal.
1. Introduction
Ces dernières années, de nombreux excellents réseaux basés sur l'apprentissage profond ont été proposés pour diverses tâches, telles que la classification d'images, la segmentation et la détection. Bien que ces réseaux fonctionnent bien sur les données d'entraînement, ils échouent inévitablement sur certaines nouvelles données qui ne sont pas entraînées dans les applications réelles. Promouvoir continuellement et efficacement les performances d'un modèle déployé sur ces nouvelles données est une demande essentielle. La solution actuelle de réentraînement du réseau en utilisant toutes les données accumulées présente deux inconvénients : 1) avec l'augmentation de la taille des données, le coût de formation devient plus élevé à chaque fois, par exemple, plus d'heures de GPU et une empreinte carbone plus importante [20], et 2) dans certains cas, les anciennes données ne sont plus accessibles en raison de la politique de confidentialité ou du budget limité pour le stockage des données. Dans le cas où peu ou pas d'anciennes données sont disponibles ou utilisées, le réentraînement du modèle d'apprentissage profond avec de nouvelles données entraîne toujours une dégradation des performances sur les anciennes données, c'est-à-dire le problème d'oubli catastrophique (CF). Pour résoudre le problème CF, l'apprentissage incrémental [4, 5, 22, 29], également connu sous le nom d'apprentissage continu, est proposé. L'apprentissage incrémental favorise considérablement la valeur pratique des modèles d'apprentissage profond et suscite un vif intérêt de recherche.
\ 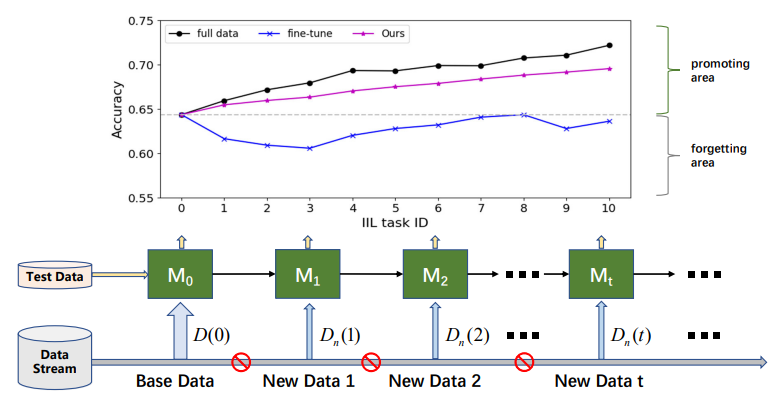
\ Selon que les nouvelles données proviennent de classes vues, l'apprentissage incrémental peut être divisé en trois scénarios [16, 17] : l'apprentissage incrémental par instance (IIL) [3, 16] où toutes les nouvelles données appartiennent aux classes vues, l'apprentissage incrémental par classe (CIL) [4, 12, 15, 22] où les nouvelles données ont des étiquettes de classe différentes, et l'apprentissage incrémental hybride [6, 30] où les nouvelles données consistent en de nouvelles observations provenant à la fois d'anciennes et de nouvelles classes. Comparé au CIL, l'IIL est relativement inexploré car il est moins susceptible au CF. Lomonaco et Maltoni [16] ont rapporté que le réglage fin d'un modèle avec arrêt précoce peut bien maîtriser le problème CF dans l'IIL. Cependant, cette conclusion ne tient pas toujours lorsqu'il n'y a pas d'accès aux anciennes données d'entraînement et que les nouvelles données ont une taille beaucoup plus petite que les anciennes données, comme illustré à la Fig. 1. Le réglage fin entraîne souvent un déplacement de la limite de décision plutôt que son expansion pour accueillir de nouvelles observations. Outre la conservation des anciennes connaissances, le déploiement réel se préoccupe davantage de la promotion efficace du modèle dans l'IIL. Par exemple, dans la détection des défauts des produits industriels, les classes de défauts sont toujours limitées aux catégories connues. Mais la morphologie de ces défauts varie de temps en temps. Les échecs sur ces défauts non vus doivent être corrigés rapidement et efficacement pour éviter que les produits défectueux ne se retrouvent sur le marché. Malheureusement, la recherche existante se concentre principalement sur la conservation des connaissances sur les anciennes données plutôt que sur l'enrichissement des connaissances avec de nouvelles observations.
\ Dans cet article, pour améliorer rapidement et de manière rentable un modèle entraîné avec de nouvelles observations de classes vues, nous définissons d'abord un nouveau paramètre IIL comme conserver les connaissances apprises ainsi que promouvoir les performances du modèle sur de nouvelles observations sans accès aux anciennes données. En termes simples, nous visons à promouvoir le modèle existant en utilisant uniquement les nouvelles données et à atteindre une performance comparable à celle du modèle réentraîné avec toutes les données accumulées. Le nouvel IIL est difficile en raison de la dérive conceptuelle [6] causée par les nouvelles observations, telles que la variation de couleur ou de forme par rapport aux anciennes données. Par conséquent, deux problèmes doivent être abordés dans le nouveau paramètre IIL : 1) l'oubli catastrophique notoire en raison de l'absence d'accès aux anciennes données, et 2) l'élargissement de la limite de décision existante aux nouvelles observations.
\ Pour résoudre les problèmes ci-dessus dans le nouveau paramètre IIL, nous proposons un nouveau cadre IIL basé sur la structure enseignant-étudiant. Le cadre proposé consiste en un processus de distillation consciente des limites de décision (DBD) et un processus de consolidation des connaissances (KC). Le DBD permet au modèle étudiant d'apprendre à partir de nouvelles observations en étant conscient des limites de décision inter-classes existantes, ce qui permet au modèle de déterminer où renforcer ses connaissances et où les conserver. Cependant, la limite de décision est introuvable lorsqu'il y a insuffisamment d'échantillons situés autour de la limite en raison de l'absence d'accès aux anciennes données dans l'IIL. Pour surmonter cela, nous nous inspirons de la pratique consistant à saupoudrer le sol de farine pour révéler les empreintes cachées. De même, nous introduisons un bruit gaussien aléatoire pour polluer l'espace d'entrée et manifester la limite de décision apprise pour la distillation. Pendant l'entraînement du modèle étudiant avec la distillation des limites, les connaissances mises à jour sont davantage consolidées vers le modèle enseignant de manière intermittente et répétée avec le mécanisme EMA [28]. L'utilisation du modèle enseignant comme modèle cible est une tentative pionnière et sa faisabilité est expliquée théoriquement.
\ Selon le nouveau paramètre IIL, nous réorganisons l'ensemble d'entraînement de certains ensembles de données existants couramment utilisés dans le CIL, tels que Cifar-100 [11] et ImageNet [24] pour établir les références. Le modèle est évalué sur les données de test ainsi que sur les données de base non disponibles à chaque phase incrémentale. Nos principales contributions peuvent être résumées comme suit : 1) Nous définissons un nouveau paramètre IIL pour rechercher une promotion rapide et rentable du modèle sur de nouvelles observations et établir les références ; 2) Nous proposons une nouvelle méthode de distillation consciente des limites de décision pour conserver les connaissances apprises ainsi que les enrichir avec de nouvelles données ; 3) Nous consolidons de manière créative les connaissances apprises de l'étudiant au modèle enseignant pour atteindre de meilleures performances et une meilleure généralisabilité, et prouvons théoriquement la faisabilité ; et 4) Des expériences approfondies démontrent que la méthode proposée accumule bien les connaissances avec seulement de nouvelles données alors que la plupart des méthodes d'apprentissage incrémental existantes ont échoué.
\
:::info Cet article est disponible sur arxiv sous la licence CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
:::info Auteurs :
(1) Qiang Nie, Université des sciences et technologies de Hong Kong (Guangzhou) ;
(2) Weifu Fu, Tencent Youtu Lab ;
(3) Yuhuan Lin, Tencent Youtu Lab ;
(4) Jialin Li, Tencent Youtu Lab ;
(5) Yifeng Zhou, Tencent Youtu Lab ;
(6) Yong Liu, Tencent Youtu Lab ;
(7) Qiang Nie, Université des sciences et technologies de Hong Kong (Guangzhou) ;
(8) Chengjie Wang, Tencent Youtu Lab.
:::
\


Vous aimerez peut-être aussi

Analyse de sécurité de BGEANX Exchange
Le projet de loi russe sur la régulation des crypto-monnaies approche du vote avec les règles de trading de la Banque de Russie

Binance Ajuste le Temps prévu du listing Spot de GENIUS et OPG d'Une Heure



