

Detalles técnicos: Entrenamiento BSGAL, Backbone Swin-L y Estrategia de Umbral Dinámico
Tabla de Enlaces
Abstracto y 1 Introducción
-
Trabajo relacionado
2.1. Aumento de Datos Generativo
2.2. Aprendizaje Activo y Análisis de Datos
-
Preliminar
-
Nuestro método
4.1. Estimación de Contribución en el Escenario Ideal
4.2. Aprendizaje Activo Generativo en Streaming por Lotes
-
Experimentos y 5.1. Configuración Offline
5.2. Configuración Online
-
Conclusión, Impacto Más Amplio y Referencias
\
A. Detalles de Implementación
B. Más ablaciones
C. Discusión
D. Visualización
A. Detalles de Implementación
A.1. Dataset
Elegimos LVIS (Gupta et al., 2019) como el dataset para nuestros experimentos. LVIS es un dataset de segmentación de instancias a gran escala, que comprende aproximadamente 160.000 imágenes con más de 2 millones de anotaciones de segmentación de instancias de alta calidad en 1203 categorías del mundo real. El dataset se divide además en tres categorías: rara, común y frecuente, según su ocurrencia en las imágenes. Las instancias marcadas como 'raras' aparecen en 1-10 imágenes, las instancias 'comunes' aparecen en 11-100 imágenes, mientras que las instancias 'frecuentes' aparecen en más de 100 imágenes. El dataset general exhibe una distribución de cola larga, que se asemeja estrechamente a la distribución de datos en el mundo real, y se aplica ampliamente en múltiples configuraciones, incluida la segmentación de pocos ejemplos (Liu et al., 2023) y la segmentación de mundo abierto (Wang et al., 2022; Zhu et al., 2023). Por lo tanto, creemos que seleccionar LVIS permite una mejor reflexión del rendimiento del modelo en escenarios del mundo real. Utilizamos las divisiones oficiales del dataset LVIS, con aproximadamente 100.000 imágenes en el conjunto de entrenamiento y 20.000 imágenes en el conjunto de validación.
A.2. Generación de Datos
Nuestro proceso de generación y anotación de datos es consistente con Zhao et al. (2023), y lo presentamos brevemente aquí. Primero usamos StableDiffusion V1.5 (Rombach et al., 2022a) (SD) como modelo generativo. Para las 1203 categorías en LVIS (Gupta et al., 2019), generamos 1000 imágenes por categoría, con resolución de imagen de 512 × 512. La plantilla de prompt para la generación es "a photo of a single {CATEGORY NAME}". Utilizamos U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023) y CLIPseg (Luddecke and Ecker, 2022) respectivamente para anotar las imágenes generativas en bruto, y seleccionamos la máscara con la puntuación CLIP más alta como anotación final. Para garantizar la calidad de los datos, las imágenes con puntuaciones CLIP por debajo de 0.21 se filtran como imágenes de baja calidad. Durante el entrenamiento, también empleamos la estrategia de pegado de instancias proporcionada por Zhao et al. (2023) para el aumento de datos. Para cada instancia, la redimensionamos aleatoriamente para que coincida con la distribución de su categoría en el conjunto de entrenamiento. El número máximo de instancias pegadas por imagen se establece en 20.
\ Además, para expandir aún más la diversidad de los datos generados y hacer nuestra investigación más universal, también utilizamos otros modelos generativos, incluidos DeepFloyd-IF (Shonenkov et al., 2023) (IF) y Perfusion (Tewel et al., 2023) (PER), con 500 imágenes por categoría por modelo. Para IF, utilizamos el modelo preentrenado proporcionado por el autor, y las imágenes generadas son la salida de la Etapa II, con una resolución de 256×256. Para PER, el modelo base que utilizamos es StableDiffusion V1.5. Para cada categoría, ajustamos el modelo utilizando las imágenes recortadas del conjunto de entrenamiento, con 400 pasos de ajuste fino. Utilizamos el modelo ajustado para generar imágenes.
\ 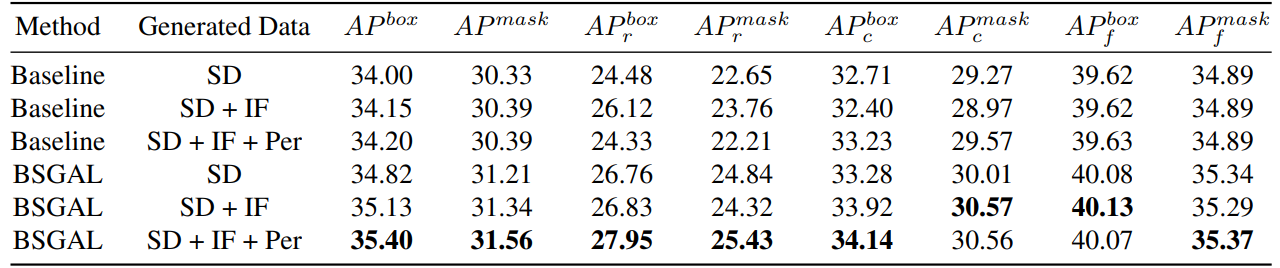
\ También exploramos el efecto de usar diferentes datos generados en el rendimiento del modelo (ver Tabla 7). Podemos ver que basado en el StableDiffusion V1.5 original, usar otros modelos generativos puede traer alguna mejora de rendimiento, pero esta mejora no es obvia. Específicamente, para categorías de frecuencia específica, encontramos que IF tiene una mejora más significativa para categorías raras, mientras que PER tiene una mejora más significativa para categorías comunes. Esto probablemente se debe a que los datos de IF son más diversos, mientras que los datos de PER son más consistentes con la distribución del conjunto de entrenamiento. Considerando que el rendimiento general ha mejorado hasta cierto punto, finalmente adoptamos los datos generados de SD + IF + PER para experimentos posteriores.
A.3. Entrenamiento del Modelo
Siguiendo a Zhao et al. (2023), utilizamos CenterNet2 (Zhou et al., 2021) como nuestro modelo de segmentación, con ResNet-50 (He et al., 2016) o Swin-L (Liu et al., 2022) como backbone. Para ResNet-50, la iteración máxima de entrenamiento se establece en 90.000 y el modelo se inicializa con pesos primero preentrenados en ImageNet-22k y luego ajustados en LVIS (Gupta et al., 2019), como Zhao
\ 
\ et al. (2023) hicieron. Y usamos 4 GPUs Nvidia 4090 con un tamaño de lote de 16 durante el entrenamiento. En cuanto a Swin-L, la iteración máxima de entrenamiento se establece en 180.000 y el modelo se inicializa con pesos preentrenados en ImageNet-22k, ya que nuestros primeros experimentos muestran que esta inicialización puede traer una ligera mejora en comparación con los pesos entrenados con LVIS. Y usamos 4 GPUs Nvidia A100 con un tamaño de lote de 16 para el entrenamiento. Además, debido al gran número de parámetros de Swin-L, la memoria adicional ocupada por guardar el gradiente es grande, por lo que en realidad usamos el algoritmo en el Algoritmo 2.
\ Los otros parámetros no especificados también siguen la misma configuración que X-Paste (Zhao et al., 2023), como el optimizador AdamW (Loshchilov and Hutter, 2017) con una tasa de aprendizaje inicial de 1e−4.
A.4. Cantidad de Datos
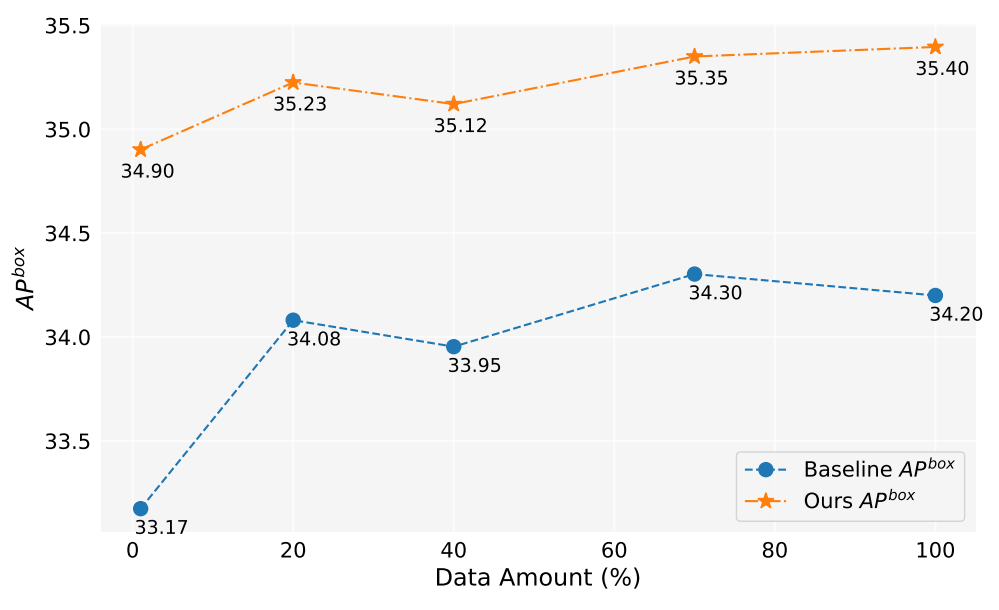
En este trabajo, hemos generado más de 2 millones de imágenes. La Figura 5 muestra los rendimientos del modelo al usar diferentes cantidades de datos generados (1%, 10%, 40%, 70%, 100%). En general, a medida que aumenta la cantidad de datos generados, el rendimiento del modelo también mejora, pero también hay cierta fluctuación. Nuestro método siempre es mejor que la línea base, lo que demuestra la efectividad y robustez de nuestro método.
A.5. Estimación de Contribución
\ Por lo tanto, esencialmente calculamos la similitud del coseno. Luego realizamos una comparación experimental, como se muestra en la Tabla 8,
\ 
\ 
\ podemos ver que si normalizamos el gradiente, nuestro método tendrá una cierta mejora. Además, dado que necesitamos mantener dos umbrales diferentes, es difícil asegurar la consistencia de la tasa de aceptación. Por lo tanto, adoptamos una estrategia de umbral dinámico, preestablecemos una tasa de aceptación, mantenemos una cola para guardar la contribución de la iteración anterior, y luego ajustamos dinámicamente el umbral de acuerdo con la cola, de modo que la tasa de aceptación se mantenga en la tasa de aceptación preestablecida.
A.6. Experimento de Juguete
Los siguientes son los ajustes experimentales específicos implementados en CIFAR-10: Empleamos un simple ResNet18 como modelo base y realizamos el entrenamiento durante 200 épocas, y la precisión después del entrenamiento en el conjunto de entrenamiento original es del 93.02%. La tasa de aprendizaje se establece en 0.1, utilizando el optimizador SGD. Un momentum de 0.9 está en efecto, con una disminución de peso de 5e-4. Utilizamos un programador de tasa de aprendizaje de enfriamiento de coseno. Las imágenes ruidosas construidas se representan en la Figura 6. Se observa una disminución en la calidad de la imagen a medida que aumenta el nivel de ruido. Notablemente, cuando el nivel de ruido alcanza 200, las imágenes se vuelven significativamente difíciles de identificar. Para la Tabla 1, usamos Split1 como R, mientras que G consiste en 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Una Simplificación Solo Avanzar Una Vez
\
:::info Autores:
(1) Muzhi Zhu, con igual contribución de la Universidad de Zhejiang, China;
(2) Chengxiang Fan, con igual contribución de la Universidad de Zhejiang, China;
(3) Hao Chen, Universidad de Zhejiang, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Universidad de Zhejiang, China;
(5) Weian Mao, Universidad de Zhejiang, China y Universidad de Adelaide, Australia;
(6) Xiaogang Xu, Universidad de Zhejiang, China;
(7) Chunhua Shen, Universidad de Zhejiang, China (chunhuashen@zju.edu.cn).
:::
:::info Este artículo está disponible en arxiv bajo la licencia CC BY-NC-ND 4.0 Deed (Atribución-NoComercial-SinDerivadas 4.0 Internacional).
:::
\
También te puede interesar

OIEA urge a reparar escudo de Chernóbil

Sheinbaum, Trump y la larga sombra de la Doctrina Monroe
