

Chi tiết kỹ thuật: Đào tạo BSGAL, Nền tảng Swin-L và Chiến lược ngưỡng động
Bảng Liên kết
Tóm tắt và 1 Giới thiệu
-
Công trình liên quan
2.1. Tăng cường dữ liệu tạo sinh
2.2. Học tập chủ động và Phân tích dữ liệu
-
Sơ bộ
-
Phương pháp của chúng tôi
4.1. Ước tính đóng góp trong kịch bản lý tưởng
4.2. Học tập chủ động tạo sinh theo lô
-
Thí nghiệm và 5.1. Cài đặt ngoại tuyến
5.2. Cài đặt trực tuyến
-
Kết luận, Tác động rộng hơn và Tài liệu tham khảo
\
A. Chi tiết triển khai
B. Thêm thử nghiệm
C. Thảo luận
D. Trực quan hóa
A. Chi tiết triển khai
A.1. Bộ dữ liệu
Chúng tôi chọn LVIS (Gupta et al., 2019) làm bộ dữ liệu cho các thí nghiệm của mình. LVIS là một bộ dữ liệu phân đoạn thể hiện quy mô lớn, bao gồm khoảng 160,000 hình ảnh với hơn 2 triệu chú thích phân đoạn thể hiện chất lượng cao trên 1203 danh mục thực tế. Bộ dữ liệu được chia thành ba danh mục: hiếm, phổ biến và thường xuyên, dựa trên sự xuất hiện của chúng trong các hình ảnh. Các thể hiện được đánh dấu là 'hiếm' xuất hiện trong 1-10 hình ảnh, các thể hiện 'phổ biến' xuất hiện trong 11-100 hình ảnh, trong khi các thể hiện 'thường xuyên' xuất hiện trong hơn 100 hình ảnh. Toàn bộ bộ dữ liệu thể hiện phân phối đuôi dài, rất giống với phân phối dữ liệu trong thế giới thực, và được áp dụng rộng rãi trong nhiều cài đặt, bao gồm phân đoạn few-shot (Liu et al., 2023) và phân đoạn thế giới mở (Wang et al., 2022; Zhu et al., 2023). Do đó, chúng tôi tin rằng việc chọn LVIS cho phép phản ánh tốt hơn hiệu suất của mô hình trong các tình huống thực tế. Chúng tôi sử dụng các phân chia bộ dữ liệu LVIS chính thức, với khoảng 100,000 hình ảnh trong tập huấn luyện và 20,000 hình ảnh trong tập xác thực.
A.2. Tạo dữ liệu
Quá trình tạo và chú thích dữ liệu của chúng tôi phù hợp với Zhao et al. (2023), và chúng tôi giới thiệu ngắn gọn ở đây. Đầu tiên, chúng tôi sử dụng StableDiffusion V1.5 (Rombach et al., 2022a) (SD) làm mô hình tạo sinh. Đối với 1203 danh mục trong LVIS (Gupta et al., 2019), chúng tôi tạo ra 1000 hình ảnh cho mỗi danh mục, với độ phân giải hình ảnh 512 × 512. Mẫu prompt cho việc tạo ra là "a photo of a single {CATEGORY NAME}". Chúng tôi sử dụng U2Net (Qin et al., 2020), SelfReformer (Yun and Lin, 2022), UFO (Su et al., 2023), và CLIPseg (Luddecke and Ecker, 2022) để chú thích các hình ảnh tạo sinh thô, và chọn mặt nạ có điểm CLIP cao nhất làm chú thích cuối cùng. Để đảm bảo chất lượng dữ liệu, các hình ảnh có điểm CLIP dưới 0.21 được lọc ra như là hình ảnh chất lượng thấp. Trong quá trình huấn luyện, chúng tôi cũng sử dụng chiến lược dán thể hiện được cung cấp bởi Zhao et al. (2023) để tăng cường dữ liệu. Đối với mỗi thể hiện, chúng tôi thay đổi kích thước ngẫu nhiên để phù hợp với phân phối của danh mục của nó trong tập huấn luyện. Số lượng tối đa các thể hiện được dán trên mỗi hình ảnh được đặt là 20.
\ Ngoài ra, để mở rộng hơn nữa sự đa dạng của dữ liệu được tạo ra và làm cho nghiên cứu của chúng tôi phổ quát hơn, chúng tôi cũng sử dụng các mô hình tạo sinh khác, bao gồm DeepFloyd-IF (Shonenkov et al., 2023) (IF) và Perfusion (Tewel et al., 2023) (PER), với 500 hình ảnh cho mỗi danh mục cho mỗi mô hình. Đối với IF, chúng tôi sử dụng mô hình được huấn luyện trước do tác giả cung cấp, và các hình ảnh được tạo ra là đầu ra của Giai đoạn II, với độ phân giải 256×256. Đối với PER, mô hình cơ sở chúng tôi sử dụng là StableDiffusion V1.5. Đối với mỗi danh mục, chúng tôi tinh chỉnh mô hình bằng cách sử dụng các hình ảnh được cắt từ tập huấn luyện, với 400 bước tinh chỉnh. Chúng tôi sử dụng mô hình đã tinh chỉnh để tạo ra hình ảnh.
\ 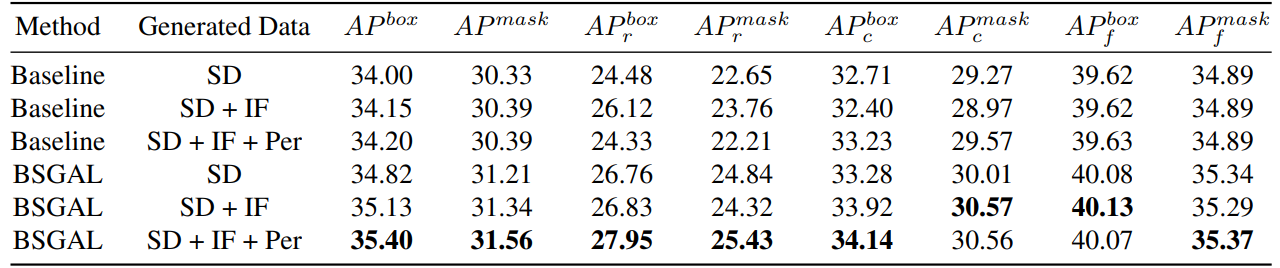
\ Chúng tôi cũng khám phá hiệu quả của việc sử dụng các dữ liệu được tạo ra khác nhau đối với hiệu suất của mô hình (xem Bảng 7). Chúng tôi có thể thấy rằng dựa trên StableDiffusion V1.5 ban đầu, việc sử dụng các mô hình tạo sinh khác có thể mang lại một số cải thiện hiệu suất, nhưng sự cải thiện này không rõ ràng. Cụ thể, đối với các danh mục tần suất cụ thể, chúng tôi nhận thấy rằng IF có sự cải thiện đáng kể hơn đối với các danh mục hiếm, trong khi PER có sự cải thiện đáng kể hơn đối với các danh mục phổ biến. Điều này có thể là do dữ liệu IF đa dạng hơn, trong khi dữ liệu PER phù hợp hơn với phân phối của tập huấn luyện. Xem xét rằng hiệu suất tổng thể đã được cải thiện đến một mức độ nhất định, cuối cùng chúng tôi áp dụng dữ liệu được tạo ra của SD + IF + PER cho các thí nghiệm tiếp theo.
A.3. Huấn luyện mô hình
Theo Zhao et al. (2023), Chúng tôi sử dụng CenterNet2 (Zhou et al., 2021) làm mô hình phân đoạn của mình, với ResNet-50 (He et al., 2016) hoặc Swin-L (Liu et al., 2022) làm xương sống. Đối với ResNet-50, số lần lặp huấn luyện tối đa được đặt là 90,000 và mô hình được khởi tạo với trọng số đầu tiên được huấn luyện trước trên ImageNet-22k sau đó được tinh chỉnh trên LVIS (Gupta et al., 2019), như Zhao
\ 
\ et al. (2023) đã làm. Và chúng tôi sử dụng 4 GPU Nvidia 4090 với kích thước lô là 16 trong quá trình huấn luyện. Đối với Swin-L, số lần lặp huấn luyện tối đa được đặt là 180,000 và mô hình được khởi tạo với trọng số được huấn luyện trước trên ImageNet-22k, vì các thí nghiệm ban đầu của chúng tôi cho thấy rằng việc khởi tạo này có thể mang lại một sự cải thiện nhỏ so với trọng số được huấn luyện với LVIS. Và chúng tôi sử dụng 4 GPU Nvidia A100 với kích thước lô là 16 cho việc huấn luyện. Ngoài ra, do số lượng tham số lớn của Swin-L, bộ nhớ bổ sung được chiếm bởi việc lưu gradient là lớn, vì vậy chúng tôi thực sự sử dụng thuật toán trong Thuật toán 2.
\ Các tham số không được chỉ định khác cũng tuân theo các cài đặt tương tự như X-Paste (Zhao et al., 2023), chẳng hạn như bộ tối ưu hóa AdamW (Loshchilov and Hutter, 2017) với tốc độ học ban đầu là 1e−4.
A.4. Lượng dữ liệu
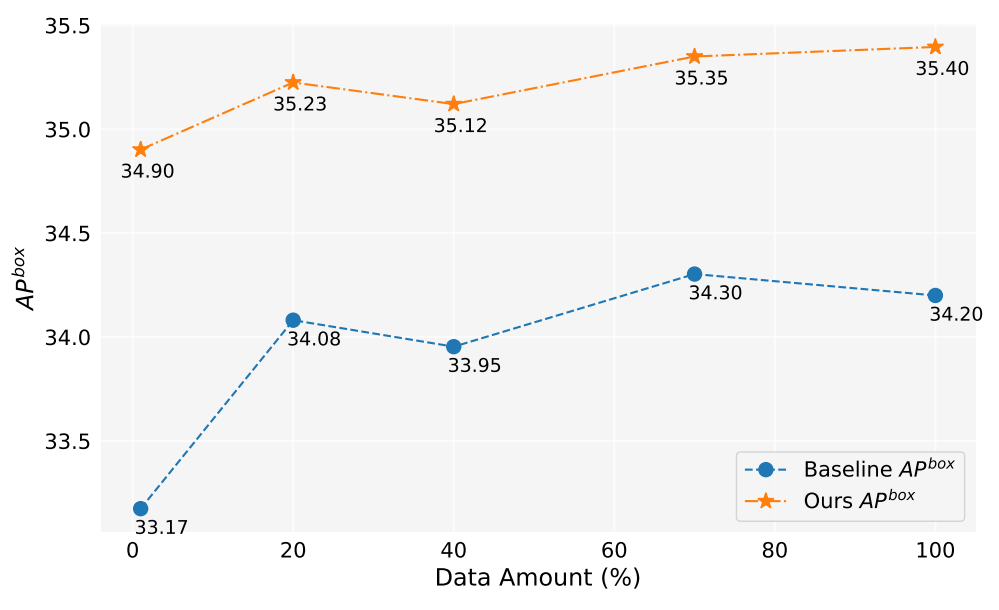
Trong công trình này, chúng tôi đã tạo ra hơn 2 triệu hình ảnh. Hình 5 cho thấy hiệu suất của mô hình khi sử dụng lượng dữ liệu được tạo ra khác nhau (1%, 10%, 40%, 70%, 100%). Nhìn chung, khi lượng dữ liệu được tạo ra tăng lên, hiệu suất của mô hình cũng cải thiện, nhưng cũng có một số dao động. Phương pháp của chúng tôi luôn tốt hơn đường cơ sở, điều này chứng minh hiệu quả và độ mạnh mẽ của phương pháp của chúng tôi.
A.5. Ước tính đóng góp
\ Do đó, về cơ bản chúng tôi tính toán độ tương đồng cosine. Sau đó chúng tôi đã tiến hành so sánh thực nghiệm, như được thể hiện trong Bảng 8,
\ 
\ 
\ chúng ta có thể thấy rằng nếu chúng ta chuẩn hóa gradient, phương pháp của chúng tôi sẽ có một sự cải thiện nhất định. Ngoài ra, vì chúng ta cần giữ hai ngưỡng khác nhau, rất khó để đảm bảo tính nhất quán của tỷ lệ chấp nhận. Vì vậy, chúng tôi áp dụng chiến lược ngưỡng động, thiết lập trước một tỷ lệ chấp nhận, duy trì một hàng đợi để lưu đóng góp của lần lặp trước đó, và sau đó điều chỉnh động ngưỡng theo hàng đợi, để tỷ lệ chấp nhận ở mức tỷ lệ chấp nhận đã thiết lập trước.
A.6. Thí nghiệm đồ chơi
Sau đây là các cài đặt thí nghiệm cụ thể được thực hiện trên CIFAR-10: Chúng tôi sử dụng một ResNet18 đơn giản làm mô hình cơ sở và tiến hành huấn luyện trong 200 epoch, và độ chính xác sau khi huấn luyện trên tập huấn luyện ban đầu là 93.02%. Tốc độ học được đặt ở mức 0.1, sử dụng bộ tối ưu hóa SGD. Một động lượng 0.9 có hiệu lực, với sự suy giảm trọng số là 5e-4. Chúng tôi sử dụng một bộ lập lịch tốc độ học cosine annealing. Các hình ảnh nhiễu được xây dựng được mô tả trong Hình 6. Sự suy giảm chất lượng hình ảnh được quan sát thấy khi mức độ nhiễu tăng lên. Đáng chú ý, khi mức độ nhiễu đạt 200, các hình ảnh trở nên khó nhận dạng đáng kể. Đối với Bảng 1, chúng tôi sử dụng Split1 làm R, trong khi G bao gồm 'Split2 + Noise40', 'Split3 + Noise100', 'Split4 + Noise200',
A.7. Một đơn giản hóa chỉ chuyển tiếp một lần
\
:::info Tác giả:
(1) Muzhi Zhu, với sự đóng góp ngang nhau từ Đại học Zhejiang, Trung Quốc;
(2) Chengxiang Fan, với sự đóng góp ngang nhau từ Đại học Zhejiang, Trung Quốc;
(3) Hao Chen, Đại học Zhejiang, Trung Quốc (haochen.cad@zju.edu.cn);
(4) Yang Liu, Đại học Zhejiang, Trung Quốc;
(5) Weian Mao, Đại học Zhejiang, Trung Quốc và Đại học Adelaide, Úc;
(6) Xiaogang Xu, Đại học Zhejiang, Trung Quốc;
(7) Chunhua Shen, Đại học Zhejiang, Trung Quốc (chunhuashen@zju.edu.cn).
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International).
:::
\
Có thể bạn cũng thích

Ra ngoài công cộng với cơn ho? Đây là hướng dẫn nhanh về cách ứng xử phù hợp

Bitcoin (BTC) Rút Về Mức $90K, Hyperliquid (HYPE) Giảm 9% Trong Ngày: Theo Dõi Thị Trường
