

Cách Các Mô Hình AI Lai Cân Bằng Bộ Nhớ và Hiệu Suất
Bảng liên kết
Tóm tắt và 1. Giới thiệu
-
Phương pháp
-
Thí nghiệm và Kết quả
3.1 Mô hình hóa ngôn ngữ trên dữ liệu vQuality
3.2 Khám phá về Attention và Tính đệ quy tuyến tính
3.3 Ngoại suy độ dài hiệu quả
3.4 Hiểu ngữ cảnh dài
-
Phân tích
-
Kết luận, Lời cảm ơn và Tài liệu tham khảo
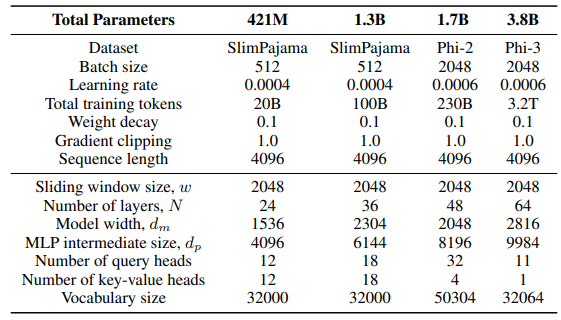
A. Chi tiết triển khai
B. Kết quả thí nghiệm bổ sung
C. Chi tiết về đo lường Entropy
D. Hạn chế
\
A Chi tiết triển khai
\ Đối với lớp GLA trong kiến trúc Sliding GLA, chúng tôi sử dụng số lượng đầu dm/384, tỷ lệ mở rộng khóa là 0.5 và tỷ lệ mở rộng giá trị là 1. Đối với lớp RetNet, chúng tôi sử dụng số lượng đầu bằng một nửa số đầu truy vấn attention, tỷ lệ mở rộng khóa là 1 và tỷ lệ mở rộng giá trị là 2. Các triển khai GLA và RetNet được lấy từ kho Flash Linear Attention[3] [YZ24]. Chúng tôi sử dụng triển khai dựa trên FlashAttention cho ngoại suy Self-Extend[4]. Mô hình Mamba 432M có độ rộng mô hình là 1024 và mô hình Mamba 1.3B có độ rộng mô hình là 2048. Tất cả các mô hình được huấn luyện trên SlimPajama đều có cấu hình huấn luyện giống nhau và kích thước trung gian MLP giống như Samba, trừ khi được chỉ định khác. Cơ sở hạ tầng huấn luyện trên SlimPajama dựa trên phiên bản sửa đổi của mã nguồn TinyLlama[5].
\ 
\ Trong cấu hình tạo ra cho các tác vụ hạ nguồn, chúng tôi sử dụng giải mã tham lam cho GSM8K và Nucleus Sampling [HBD+19] với nhiệt độ τ = 0.2 và top-p = 0.95 cho HumanEval. Đối với MBPP và SQuAD, chúng tôi đặt τ = 0.01 và top-p = 0.95.
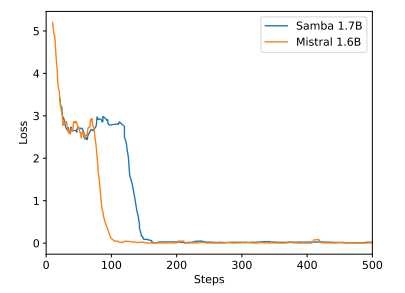
B Kết quả thí nghiệm bổ sung
\ 
\ 
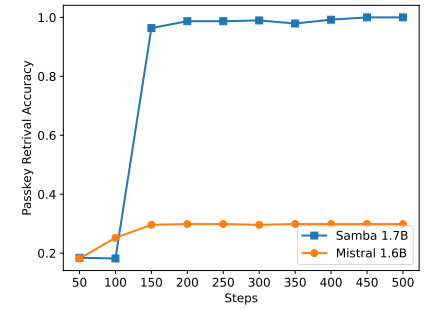
\ 
\
C Chi tiết về đo lường Entropy
\ 
\
D Hạn chế
Mặc dù Samba thể hiện hiệu suất truy xuất bộ nhớ đầy hứa hẹn thông qua điều chỉnh hướng dẫn, mô hình cơ sở được huấn luyện trước của nó có hiệu suất truy xuất tương tự như mô hình dựa trên SWA, như được hiển thị trong Hình 7. Điều này mở ra hướng phát triển trong tương lai để cải thiện hơn nữa khả năng truy xuất của Samba mà không ảnh hưởng đến hiệu quả và khả năng ngoại suy của nó. Ngoài ra, chiến lược lai hóa của Samba không nhất quán tốt hơn các phương án thay thế khác trong tất cả các tác vụ. Như được hiển thị trong Bảng 2, MambaSWA-MLP cho thấy hiệu suất cải thiện trên các tác vụ như WinoGrande, SIQA và GSM8K. Điều này mang lại cho chúng tôi tiềm năng đầu tư vào một phương pháp tinh vi hơn để thực hiện kết hợp động phụ thuộc vào đầu vào của các mô hình dựa trên SWA và dựa trên SSM.
\
:::info Tác giả:
(1) Liliang Ren, Microsoft và University of Illinois at Urbana-Champaign (liliangren@microsoft.com);
(2) Yang Liu†, Microsoft (yaliu10@microsoft.com);
(3) Yadong Lu†, Microsoft (yadonglu@microsoft.com);
(4) Yelong Shen, Microsoft (yelong.shen@microsoft.com);
(5) Chen Liang, Microsoft (chenliang1@microsoft.com);
(6) Weizhu Chen, Microsoft (wzchen@microsoft.com).
:::
:::info Bài báo này có sẵn trên arxiv theo giấy phép CC BY 4.0.
:::
[3] https://github.com/sustcsonglin/flash-linear-attention
\ [4] https://github.com/datamllab/LongLM/blob/master/selfextendpatch/Llama.py
\ [5] https://github.com/jzhang38/TinyLlama
Có thể bạn cũng thích

Tòa án bác bỏ yêu cầu hủy vụ án tham ô kỹ thuật đối với Matugas của Surigao del Norte

Cải cách của FCA Anh phân biệt Nhà đầu tư bán lẻ và Nhà giao dịch chuyên nghiệp
