

Giải quyết nút thắt lớn nhất của phân đoạn 3D
:::info Authors:
(1) George Tang, Massachusetts Institute of Technology;
(2) Krishna Murthy Jatavallabhula, Massachusetts Institute of Technology;
(3) Antonio Torralba, Massachusetts Institute of Technology.
:::
Table of Links
Abstract and I. Introduction
II. Background
III. Method
IV. Experiments
V. Conclusion and References
\ 
\ Abstract— Chúng tôi giải quyết vấn đề học biểu diễn cảnh ngầm cho phân đoạn thể hiện 3D từ một chuỗi ảnh RGB có tư thế. Hướng tới điều này, chúng tôi giới thiệu 3DIML, một framework mới hiệu quả học một trường nhãn có thể được hiển thị từ các góc nhìn mới để tạo ra các mặt nạ phân đoạn thể hiện nhất quán theo góc nhìn. 3DIML cải thiện đáng kể thời gian chạy đào tạo và suy luận của các phương pháp dựa trên biểu diễn cảnh ngầm hiện có. Trái ngược với các phương pháp trước đây tối ưu hóa một trường neural theo cách tự giám sát, đòi hỏi các quy trình đào tạo phức tạp và thiết kế hàm mất mát, 3DIML tận dụng quy trình hai giai đoạn. Giai đoạn đầu tiên, InstanceMap, lấy đầu vào là các mặt nạ phân đoạn 2D của chuỗi hình ảnh được tạo ra bởi một mô hình phân đoạn thể hiện frontend, và liên kết các mặt nạ tương ứng trên các hình ảnh với các nhãn 3D. Những mặt nạ pseudolabel gần như nhất quán theo góc nhìn này sau đó được sử dụng trong giai đoạn thứ hai, InstanceLift, để giám sát việc đào tạo một trường nhãn neural, nội suy các vùng bị bỏ sót bởi InstanceMap và giải quyết các mơ hồ. Ngoài ra, chúng tôi giới thiệu InstanceLoc, cho phép định vị gần thời gian thực các mặt nạ thể hiện với một trường nhãn đã được đào tạo và một mô hình phân đoạn hình ảnh có sẵn bằng cách kết hợp đầu ra từ cả hai. Chúng tôi đánh giá 3DIML trên các chuỗi từ bộ dữ liệu Replica và ScanNet và chứng minh hiệu quả của 3DIML dưới các giả định nhẹ cho các chuỗi hình ảnh. Chúng tôi đạt được tăng tốc thực tế lớn so với các phương pháp biểu diễn cảnh ngầm hiện có với chất lượng tương đương, thể hiện tiềm năng của nó để tạo điều kiện cho việc hiểu cảnh 3D nhanh hơn và hiệu quả hơn.
I. INTRODUCTION
Các tác nhân thông minh đòi hỏi sự hiểu biết về cảnh ở cấp độ đối tượng để thực hiện hiệu quả các hành động theo ngữ cảnh cụ thể như điều hướng và thao tác. Mặc dù việc phân đoạn đối tượng từ hình ảnh đã đạt được tiến bộ đáng kể với các mô hình có khả năng mở rộng được đào tạo trên các bộ dữ liệu quy mô internet [1], [2], việc mở rộng các khả năng như vậy sang môi trường 3D vẫn còn nhiều thách thức.
\ Trong công trình này, chúng tôi giải quyết vấn đề học biểu diễn cảnh 3D từ các hình ảnh 2D có tư thế phân tách cảnh cơ bản thành tập hợp các đối tượng cấu thành của nó. Các phương pháp hiện có để giải quyết vấn đề này đã tập trung vào việc đào tạo các mô hình phân đoạn 3D không phân biệt lớp [3], [4], đòi hỏi lượng lớn dữ liệu 3D được chú thích, và hoạt động trực tiếp trên các biểu diễn cảnh 3D rõ ràng (ví dụ: đám mây điểm). Một lớp phương pháp thay thế [5], [6] đã đề xuất nâng trực tiếp các mặt nạ phân đoạn từ các mô hình phân đoạn thể hiện có sẵn thành các biểu diễn 3D ngầm, chẳng hạn như các trường bức xạ neural (NeRF) [7], cho phép chúng hiển thị các mặt nạ thể hiện nhất quán 3D từ các góc nhìn mới.
\ Tuy nhiên, các phương pháp dựa trên trường neural vẫn nổi tiếng khó tối ưu hóa, với [5] và [6] mất nhiều giờ để tối ưu hóa cho hình ảnh có độ phân giải thấp đến trung bình (ví dụ: 300 × 640). Đặc biệt, Panoptic Lifting [5] tăng theo hàm mũ ba với số lượng đối tượng trong cảnh, ngăn cản việc áp dụng nó cho các cảnh có hàng trăm đối tượng, trong khi Contrastively Lifting [6] đòi hỏi một quy trình đào tạo nhiều giai đoạn phức tạp, cản trở tính thực tế cho việc sử dụng trong các ứng dụng robot.
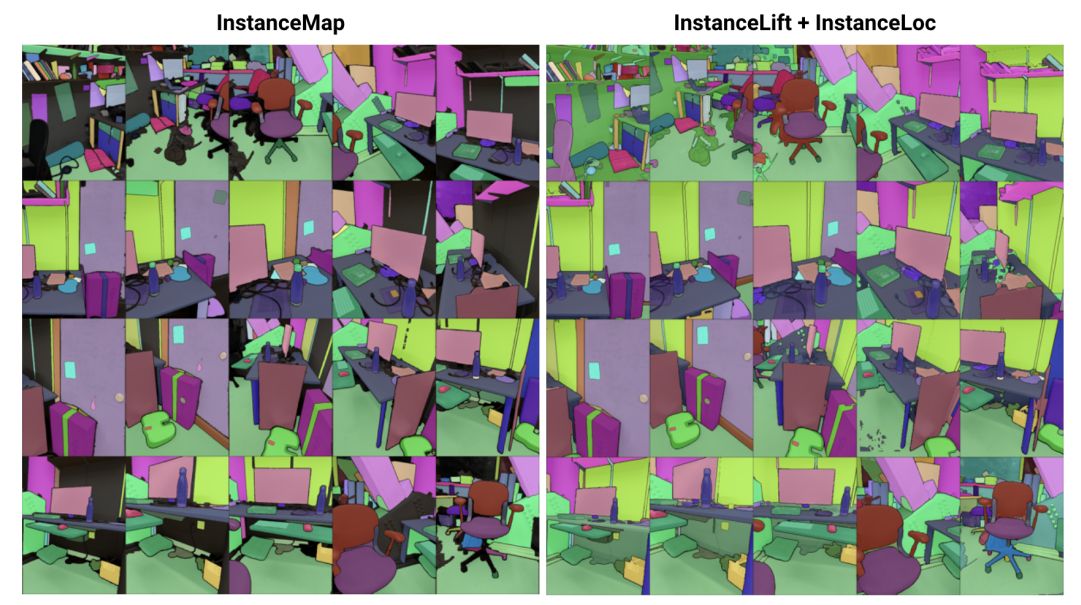
\ Để đạt được điều này, chúng tôi đề xuất 3DIML, một kỹ thuật hiệu quả để học phân đoạn thể hiện nhất quán 3D từ các hình ảnh RGB có tư thế. 3DIML bao gồm hai giai đoạn: InstanceMap và InstanceLift. Với các mặt nạ thể hiện 2D không nhất quán theo góc nhìn được trích xuất từ chuỗi RGB sử dụng mô hình phân đoạn thể hiện frontend [2], InstanceMap tạo ra một chuỗi các mặt nạ thể hiện nhất quán theo góc nhìn. Để làm điều này, trước tiên chúng tôi liên kết các mặt nạ trên các khung hình bằng cách sử dụng các điểm khớp giữa các cặp hình ảnh tương tự. Sau đó, chúng tôi sử dụng các liên kết có thể nhiễu này để giám sát một trường nhãn neural, InstanceLift, khai thác cấu trúc 3D để nội suy các nhãn bị thiếu và giải quyết các mơ hồ. Không giống như các công trình trước đây, đòi hỏi đào tạo nhiều giai đoạn và thiết kế hàm mất mát bổ sung, chúng tôi sử dụng một hàm mất mát hiển thị duy nhất cho việc giám sát nhãn thể hiện, cho phép quá trình đào tạo hội tụ nhanh hơn đáng kể. Tổng thời gian chạy của 3DIML, bao gồm InstanceMap, mất 10-20 phút, so với 3-6 giờ cho các phương pháp trước đây.
\ Ngoài ra, chúng tôi thiết kế InstaLoc, một pipeline định vị nhanh nhận vào một góc nhìn mới và định vị tất cả các thể hiện được phân đoạn trong hình ảnh đó (sử dụng một mô hình phân đoạn thể hiện nhanh [8]) bằng cách truy vấn thưa thớt trường nhãn và kết hợp các dự đoán nhãn với các vùng hình ảnh được trích xuất. Cuối cùng, 3DIML cực kỳ mô-đun, và chúng tôi có thể dễ dàng thay thế các thành phần của phương pháp của chúng tôi bằng các thành phần hiệu quả hơn khi chúng có sẵn.
\ Tóm lại, những đóng góp của chúng tôi là:
\ • Một phương pháp học trường neural hiệu quả phân tách một cảnh 3D thành các đối tượng cấu thành của nó
\ • Một thuật toán định vị thể hiện nhanh kết hợp các truy vấn thưa thớt đến trường nhãn đã đào tạo với các mô hình phân đoạn thể hiện hình ảnh hiệu quả để tạo ra các mặt nạ phân đoạn thể hiện nhất quán 3D
\ • Một cải thiện thời gian chạy thực tế tổng thể 14-24× so với các phương pháp trước đây được đánh giá trên một GPU (NVIDIA RTX 3090)
II. BACKGROUND
Phân đoạn 2D: Sự phổ biến của kiến trúc vision transformer và quy mô ngày càng tăng của các bộ dữ liệu hình ảnh đã dẫn đến một loạt các mô hình phân đoạn hình ảnh tiên tiến. Panoptic và Contrastive Lifting đều nâng các mặt nạ phân đoạn panoptic được tạo ra bởi Mask2Former [1] lên 3D bằng cách học một trường neural. Hướng tới phân đoạn tập mở, segment anything (SAM) [2] đạt được hiệu suất chưa từng có bằng cách đào tạo trên một tỷ mặt nạ trên 11 triệu hình ảnh. HQ-SAM [9] cải thiện SAM cho các mặt nạ chi tiết. FastSAM [8] chưng cất SAM thành kiến trúc CNN và đạt được hiệu suất tương tự trong khi nhanh hơn nhiều lần. Trong công trình này, chúng tôi sử dụng GroundedSAM [10], [11], tinh chỉnh SAM để tạo ra các mặt nạ phân đoạn cấp đối tượng, thay vì cấp bộ phận.
\ Các trường neural cho phân đoạn thể hiện 3D: NeRF là các biểu diễn cảnh ngầm có thể mã hóa chính xác hình học phức tạp, ngữ nghĩa và các phương thức khác, cũng như giải quyết sự giám sát không nhất quán theo góc nhìn [12]. Panoptic lifting [5] xây dựng các nhánh ngữ nghĩa và thể hiện trên một biến thể hiệu quả của NeRF, TensoRF [13], sử dụng hàm mất mát khớp Hungarian để gán các mặt nạ thể hiện đã học cho các ID đối tượng thay thế dựa trên các mặt nạ tham chiếu không nhất quán theo góc nhìn. Điều này mở rộng kém với số lượng đối tượng tăng lên (do độ phức tạp lập phương của khớp Hungarian). Contrastive lifting [6] giải quyết vấn đề này bằng cách sử dụng học đối lập trên các đặc trưng cảnh, với các mối quan hệ tích cực và tiêu cực được xác định bởi việc chúng có chiếu lên cùng một mặt nạ hay không. Ngoài ra, contrastive lifting đòi hỏi một hàm mất mát dựa trên phân cụm chậm-nhanh để đào tạo ổn định, dẫn đến hiệu suất nhanh hơn so với panoptic lifting nhưng đòi hỏi nhiều giai đoạn đào tạo, dẫn đến hội tụ chậm. Đồng thời với chúng tôi, Instance-NeRF [14] trực tiếp học một trường nhãn, nhưng họ dựa vào việc sử dụng NeRF-RPN [15] để phát hiện đối t
Có thể bạn cũng thích

Polygon triển khai Hard Fork Madhugiri, hướng tới tăng 33% thông lượng

Cổ phiếu Nvidia (NVDA): Chính quyền Trump phê duyệt xuất khẩu chip H200 sang Trung Quốc
