

New IIL Setting: Enhancing Deployed Models with Only New Data
Table of Links
Abstract and 1 Introduction
-
Related works
-
Problem setting
-
Methodology
4.1. Decision boundary-aware distillation
4.2. Knowledge consolidation
-
Experimental results and 5.1. Experiment Setup
5.2. Comparison with SOTA methods
5.3. Ablation study
-
Conclusion and future work and References
\
Supplementary Material
- Details of the theoretical analysis on KCEMA mechanism in IIL
- Algorithm overview
- Dataset details
- Implementation details
- Visualization of dusted input images
- More experimental results
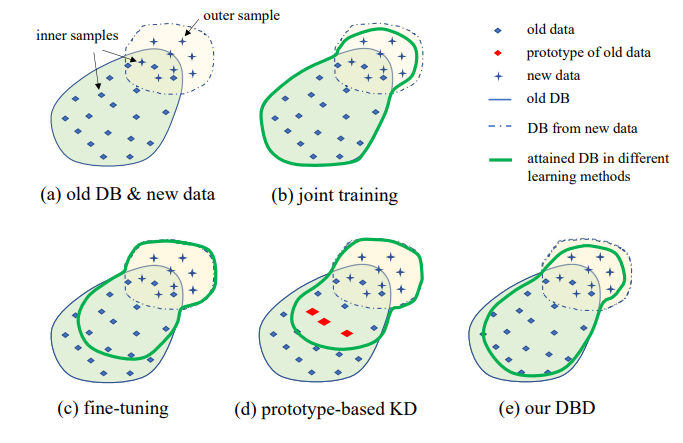
3. Problem setting
Illustration of the proposed IIL setting is shown in Fig. 1. As can be seen, data is generated continually and unpredictably in the data stream. Generally in real application, people incline to collect enough data first and train a strong model M0 for deployment. No matter how strong the model is, it inevitably will encounter out-of-distribution data and fail on it. These failed cases and other low-score new observations will be annotated to train the model from time to time. Retraining the model with all cumulate data every time leads to higher and higher cost in time and resource. Therefore, the new IIL aims to enhance the existing model with only the new data each time.
\ 
\ 
\
:::info Authors:
(1) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(2) Weifu Fu, Tencent Youtu Lab;
(3) Yuhuan Lin, Tencent Youtu Lab;
(4) Jialin Li, Tencent Youtu Lab;
(5) Yifeng Zhou, Tencent Youtu Lab;
(6) Yong Liu, Tencent Youtu Lab;
(7) Qiang Nie, Hong Kong University of Science and Technology (Guangzhou);
(8) Chengjie Wang, Tencent Youtu Lab.
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\
Ayrıca Şunları da Beğenebilirsiniz

CME Unleashing XRP Options After $16B Futures Rally Signals Strong Institutional Demand

What Devs Are Actually Doing
