

Ускорьте свои конвейеры данных в 5 раз с помощью адаптивной пакетной обработки
У вас есть массовые вызовы LLM в потоке преобразования данных?
CocoIndex может помочь. Он работает на сверхпроизводительном движке Rust и теперь поддерживает адаптивную пакетную обработку из коробки. Это улучшило пропускную способность примерно в 5 раз (≈80% более быстрое время выполнения) для нативных рабочих процессов ИИ. И что самое лучшее, вам не нужно менять код, потому что пакетная обработка происходит автоматически, адаптируясь к вашему трафику и обеспечивая полное использование GPU.
Вот что мы узнали при создании поддержки адаптивной пакетной обработки в Cocoindex.
Но сначала давайте ответим на некоторые вопросы, которые могут возникнуть.
Почему пакетная обработка ускоряет процесс?
-
Фиксированные накладные расходы на вызов: Это включает всю подготовительную и административную работу, необходимую до начала фактических вычислений. Примеры включают настройку запуска ядра GPU, переходы Python-to-C/C++, планирование задач, выделение и управление памятью, а также учет, выполняемый фреймворком. Эти накладные задачи в значительной степени не зависят от размера входных данных, но должны полностью оплачиваться для каждого вызова.
\
-
Работа, зависящая от данных: Эта часть вычислений напрямую масштабируется с размером и сложностью входных данных. Она включает операции с плавающей запятой (FLOPs), выполняемые моделью, перемещение данных по иерархиям памяти, обработку токенов и другие операции, специфичные для входных данных. В отличие от фиксированных накладных расходов, эта стоимость увеличивается пропорционально объему обрабатываемых данных.
Когда элементы обрабатываются по отдельности, фиксированные накладные расходы возникают повторно для каждого элемента, что может быстро доминировать в общем времени выполнения, особенно когда вычисления на элемент относительно малы. Напротив, обработка нескольких элементов вместе в пакетах значительно снижает влияние этих накладных расходов на каждый элемент. Пакетная обработка позволяет распределить фиксированные затраты на множество элементов, а также обеспечивает аппаратные и программные оптимизации, которые повышают эффективность работы, зависящей от данных. Эти оптимизации включают более эффективное использование конвейеров GPU, лучшее использование кэша и меньшее количество запусков ядра, что способствует повышению пропускной способности и снижению общей задержки.
\
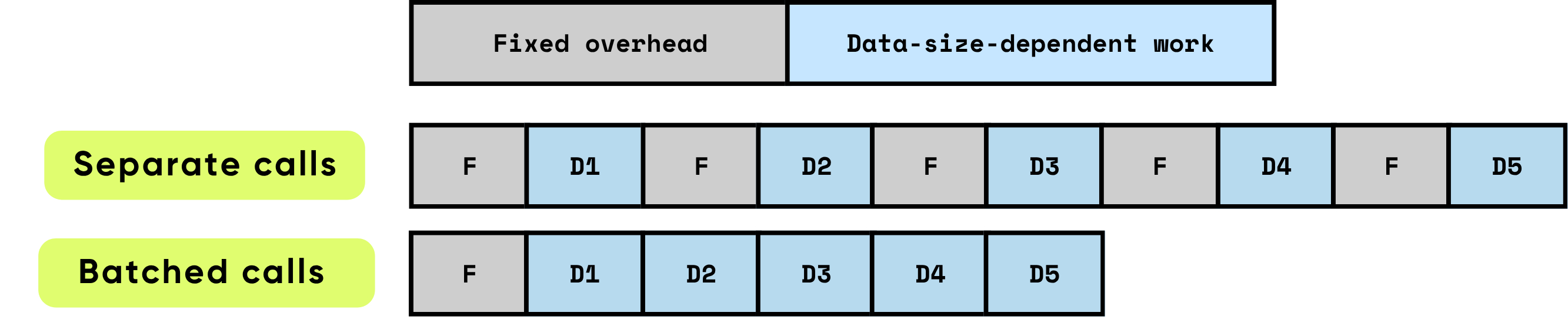
\ Пакетная обработка значительно улучшает производительность, оптимизируя как вычислительную эффективность, так и использование ресурсов. Она обеспечивает множество совокупных преимуществ:
\
-
Амортизация разовых накладных расходов: Каждый вызов функции или API несет фиксированные накладные расходы — запуски ядра GPU, переходы Python-to-C/C++, планирование задач, управление памятью и учет фреймворка. Обрабатывая элементы в пакетах, эти накладные расходы распределяются на множество входных данных, резко снижая стоимость на элемент и устраняя повторяющуюся работу по настройке.
\
-
Максимизация эффективности GPU: Более крупные пакеты позволяют GPU выполнять операции как плотные, высокопараллельные умножения матриц, обычно реализуемые как умножение матрицы на матрицу (GEMM). Это отображение обеспечивает работу оборудования с более высокой утилизацией, полностью используя параллельные вычислительные блоки, минимизируя простои и достигая пиковой пропускной способности. Малые, необработанные операции оставляют большую часть GPU недоиспользованной, тратя дорогостоящие вычислительные мощности.
\
-
Снижение накладных расходов на передачу данных: Пакетная обработка минимизирует частоту передачи памяти между CPU (хост) и GPU (устройство). Меньшее количество операций Host-to-Device (H2D) и Device-to-Host (D2H) означает меньше времени на перемещение данных и больше времени на фактические вычисления. Это критично для высокопроизводительных систем, где пропускная способность памяти часто становится ограничивающим фактором, а не сырая вычислительная мощность.
В совокупности эти эффекты приводят к улучшениям пропускной способности на порядки. Пакетная обработка превращает множество мелких, неэффективных вычислений в крупные, высокооптимизированные операции, которые полностью используют возможности современного оборудования. Для рабочих нагрузок ИИ — включая большие языковые модели, компьютерное зрение и обработку данных в реальном времени — пакетная обработка не просто оптимизация; она необходима для достижения масштабируемой производительности промышленного уровня.
\
Как выглядит пакетная обработка для обычного кода Python
Код без пакетной обработки – простой, но менее эффективный
Самый естественный способ организовать конвейер – обрабатывать данные по частям. Например, двухуровневый цикл, как этот:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Это легко читать и понимать: каждый фрагмент проходит прямо через несколько шагов.
Ручная пакетная обработка – более эффективная, но сложная
Вы можете ускорить это с помощью пакетной обработки, но даже самая простая версия "просто обработать все за раз" делает код значительно сложнее:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
Более того, обработка всего сразу обычно не идеальна, потому что следующие шаги могут начаться только после того, как этот шаг будет выполнен для всех данных.
Поддержка пакетной обработки в CocoIndex
CocoIndex устраняет разрыв и позволяет получить лучшее из обоих миров – сохранить простоту вашего кода, следуя естественному потоку, при этом получая эффективность от пакетной обработки, предоставляемой средой выполнения CocoIndex.
Мы уже включили поддержку пакетной обработки для следующих встроенных функций:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
Это не меняет API. Ваш существующий код будет работать без изменений – по-прежнему следуя естественному потоку, при этом наслаждаясь эффективностью пакетной обработки.
Для пользовательских функций включение пакетной обработки так же просто, как:
- Установить
batching=Trueв декораторе пользовательской функции. - Изменить аргументы и тип возвращаемого значения на
list.
Например, если вы хотите создать пользовательскую функцию, которая вызывает API для создания миниатюр изображений.
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip Смотрите документацию по пакетной обработке для получения дополнительной информации.
:::
Как CocoIndex выполняет пакетную обработку
Общие подходы
Пакетная обработка работает путем сбора входящих запросов в очередь и определения правильного момента для их отправки в виде единого пакета. Этот выбор времени имеет решающее значение — если сделать это правильно, вы сбалансируете пропускную способность, задержку и использование ресурсов одновременно.
Два широко используемых подхода к пакетной обработке доминируют в ландшафте:
- Пакетная обработка на основе времени (отправка каждые W миллисекунд): В этом подходе система отправляет все запросы, которые поступили в течение фиксированного окна W миллисекунд.
-
Преимущества: Максимальное время ожидания для любого запроса предсказуемо, а реализация проста. Это гарантирует, что даже при низком трафике запросы не останутся в очереди бесконечно.
-
Недостатки: В периоды редкого трафика простаивающие запросы накапливаются медленно, добавляя задержку для ранних прибытий. Кроме того, оптимальное окно W часто варьируется в зависимости от характеристик рабочей нагрузки, требуя тщательной настройки для достижения правильного баланса между задержкой и пропускной способностью.
\
- Пакетная обработка на основе размера (отправка, когда в очереди K элементов): Здесь пакет запускается, как только очередь достигает предопределенного количества элементов, K.
- Преимущества: Размер пакета предсказуем, что упрощает управление памятью и дизайн системы. Легко рассуждать о ресурсах, которые будет потреблять каждый пакет.
- Недостатки: Когда трафик низкий, запросы могут оставаться в очереди в течение длительного периода, увеличивая задержку для первых прибывших элементов. Как и в случае с пакетной обработкой на основе времени, оптимальное K зависит от шаблонов рабочей нагрузки, требуя эмпирической настройки.
Многие высокопроизводительные системы принимают гибридный подход: они отправляют пакет, когда либо истекает временное окно W, либо очередь достигает размера K — в зависимости от того, что наступит раньше. Эта стратегия объединяет преимущества обоих методов, улучшая отзывчивость при редком трафике, сохраняя при этом э


Вам также может быть интересно

Ведущий MS NOW указывает момент, когда Пэм Бонди стала «посмешищем»

Mintellect заключает партнерство с ChainAware для развития Web3 на базе ИИ


