

Syntactically Valid Code Editing: A Training Methodology for Neural Program Synthesis
Table of Links
Abstract and 1. Introduction
-
Background & Related Work
-
Method
3.1 Sampling Small Mutations
3.2 Policy
3.3 Value Network & Search
3.4 Architecture
-
Experiments
4.1 Environments
4.2 Baselines
4.3 Ablations
-
Conclusion, Acknowledgments and Disclosure of Funding, and References
\
Appendix
A. Mutation Algorithm
B. Context-Free Grammars
C. Sketch Simulation
D. Complexity Filtering
E. Tree Path Algorithm
F. Implementation Details
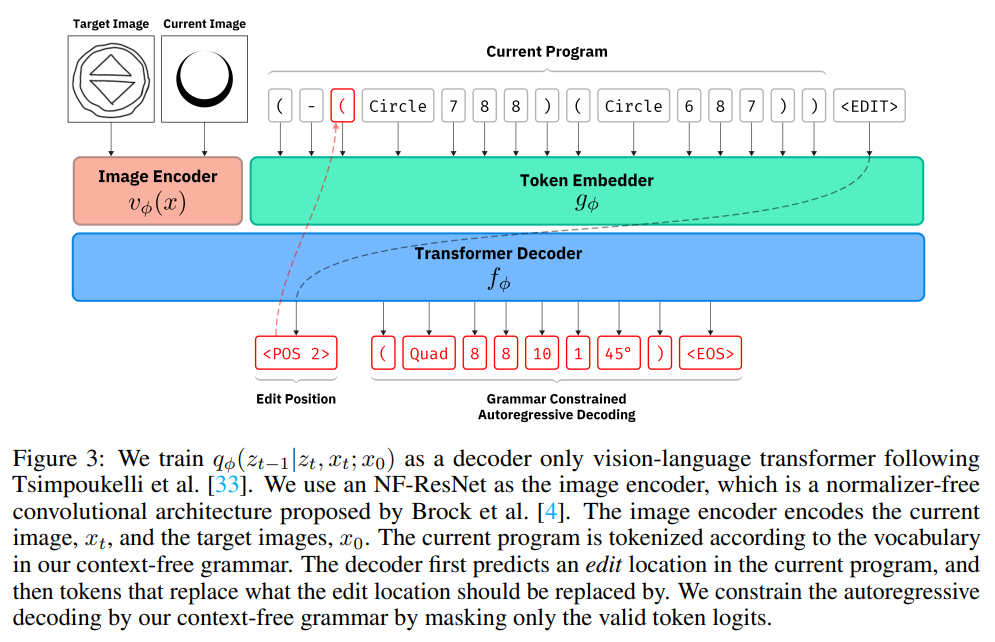
3.4 Architecture

\ We add two additional types of tokens: an token, which serves as a start-of-sentence token for the model; and tokens, which allow the model to reference positions within its context. Given a current image, a target image, and a current tokenized program, we train this transformer model to predict the edit position and the replacement text autoregressively. While making predictions, the decoding is constrained under the grammar. We mask out the prediction logits to only include edit positions that represent nodes in the syntax tree, and only produce replacements that are syntactically valid for the selected edit position.
\ We set σsmall = 2, which means the network is only allowed to produce edits with fewer than two primitives. For training data, we sample an infinite stream of random expressions from the CFG. We choose a random number of noise steps, s ∈ [1, 5], to produce a mutated expression. For some percentage of the examples, ρ, we instead sample a completely random new expression as our mutated expression. We trained for 3 days for the environments we tested on a single Nvidia A6000 GPU.
\ 
\
:::info Authors:
(1) Shreyas Kapur, University of California, Berkeley (srkp@cs.berkeley.edu);
(2) Erik Jenner, University of California, Berkeley (jenner@cs.berkeley.edu);
(3) Stuart Russell, University of California, Berkeley (russell@cs.berkeley.edu).
:::
:::info This paper is available on arxiv under CC BY-SA 4.0 DEED license.
:::
\
추천 콘텐츠

TIEZA Partners with GCash to Digitise Travel Tax Refunds

