

The Role of Consistency and Sharing in Efficient Fine-Tuning
Table of Links
Abstract and 1. Introduction
-
Background
2.1 Mixture-of-Experts
2.2 Adapters
-
Mixture-of-Adaptations
3.1 Routing Policy
3.2 Consistency regularization
3.3 Adaptation module merging and 3.4 Adaptation module sharing
3.5 Connection to Bayesian Neural Networks and Model Ensembling
-
Experiments
4.1 Experimental Setup
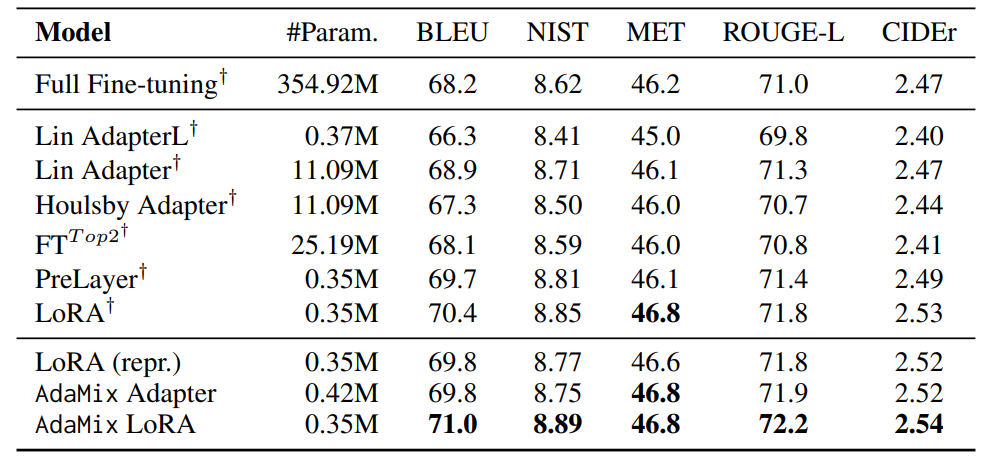
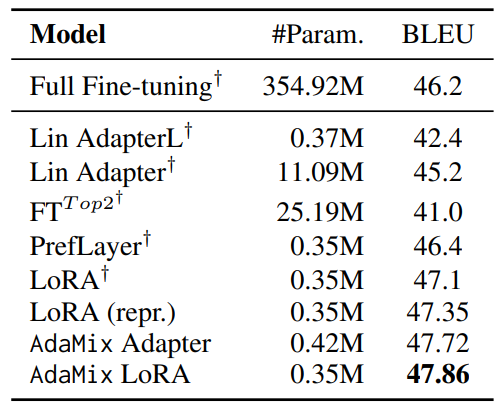
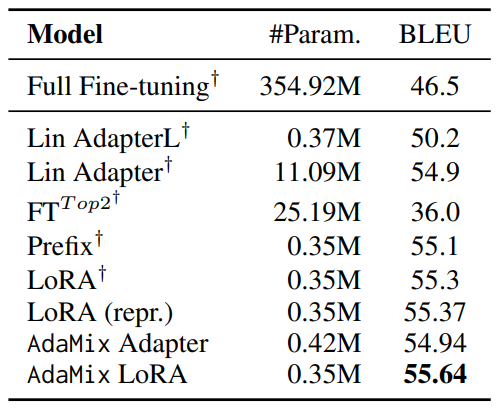
4.2 Key Results
4.3 Ablation Study
-
Related Work
-
Conclusions
-
Limitations
-
Acknowledgment and References
Appendix
A. Few-shot NLU Datasets B. Ablation Study C. Detailed Results on NLU Tasks D. Hyper-parameter
4.3 Ablation Study
We perform all the ablation analysis on AdaMix with adapters for parameter-efficient fine-tuning.
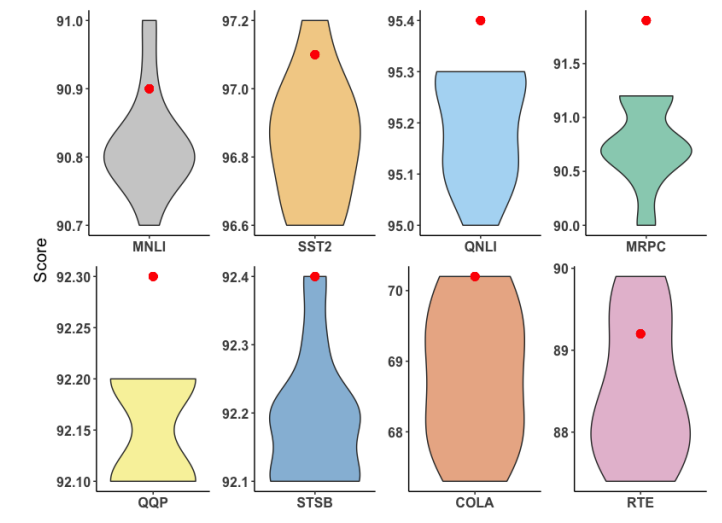
\ Analysis of adaptation merging. In this ablation study, we do not merge adaptation modules and consider two different routing strategies at inference time: (a) randomly routing input to any adaptation module, and (b) fixed routing where we route all the input to the first adaptation module in AdaMix. From Table 7, we observe AdaMix with adaptation merging to perform better than any of the other variants without the merging mechanism. Notably, all of the AdaMix variants outperform full model tuning.
\ 
\ 
\ Moreover, Figure 5 shows that the performance of merging mechanism is consistently better than the average performance of random routing and comparable to the best performance of random routing.
\ \ \ 
\ 
\ Analysis of consistency regularization. We drop consistency regularization during training for ablation and demonstrate significant performance degradation in Table 8.
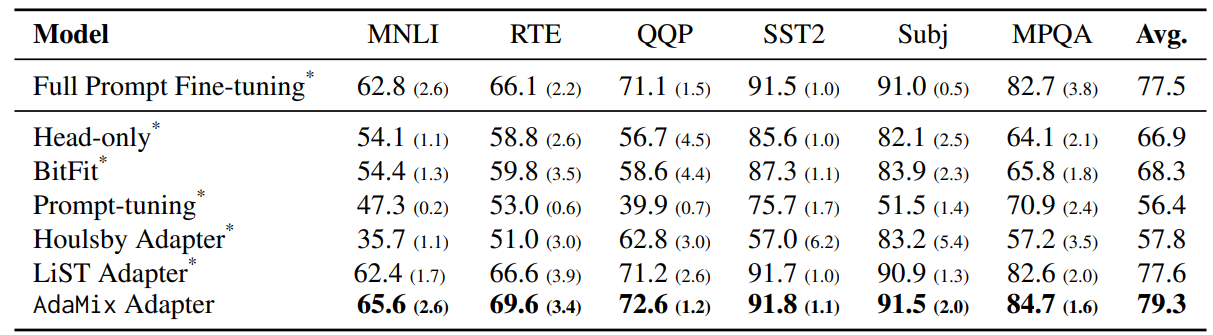
\ Analysis of adaptation module sharing. We remove adaptation module sharing in AdaMix for ablation and keep four different copies of projectdown and four project-up FFN layers. From Table 8 we observe the performance gap between AdaMix and AdaMix w/o sharing to increase with decrease in the dataset size demonstrating the importance of parameter sharing for low-resource tasks (e.g.,
\ 
\ 
\ 
\ 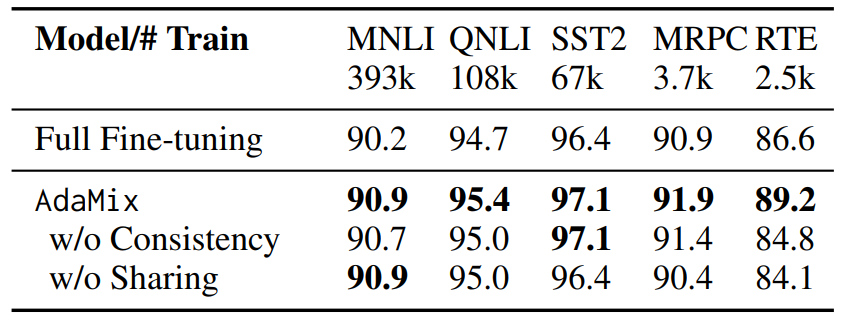
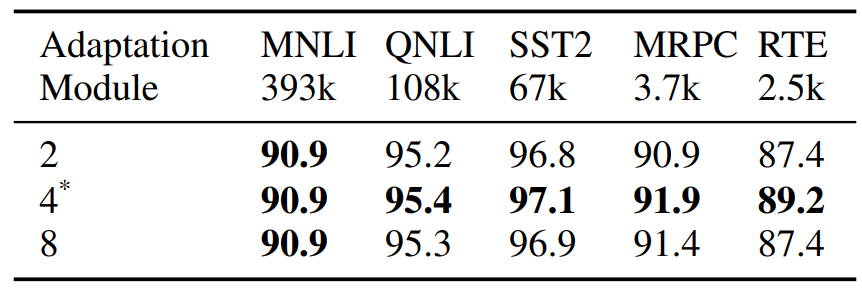
\ RTE, MRPC). This is further demonstrated in Figure 7 in Appendix which shows a faster convergence and lower training loss of AdaMix with sharing compared to that without given the same number of training steps. We explore which adaptation module to share (project-up v.s. project-down) in Table 11 in Appendix that depict similar results. Impact of the number of adaptation modules. In this study, we vary the number of adaptation modules in AdaMix as 2, 4 and 8 during training. Table 9 shows diminishing returns on aggregate task performance with increasing number of modules. As we increase sparsity and the number of tunable parameters by increasing the number of adaptation modules, low-resource tasks like RTE and SST-2 – with limited amount of labeled data for fine-tuning – degrade in performance compared to high-resource tasks like MNLI and QNLI.
\ 
\ Impact of adapter bottleneck dimension. Table 10 shows the impact of bottleneck dimension of adapters with different encoders in AdaMix. The model performance improves with increase in the number of trainable parameters by increasing the bottleneck dimension with diminishing returns after a certain point.
\
:::info Authors:
(1) Yaqing Wang, Purdue University (wang5075@purdue.edu);
(2) Sahaj Agarwal, Microsoft (sahagar@microsoft.com);
(3) Subhabrata Mukherjee, Microsoft Research (submukhe@microsoft.com);
(4) Xiaodong Liu, Microsoft Research (xiaodl@microsoft.com);
(5) Jing Gao, Purdue University (jinggao@purdue.edu);
(6) Ahmed Hassan Awadallah, Microsoft Research (hassanam@microsoft.com);
(7) Jianfeng Gao, Microsoft Research (jfgao@microsoft.com).
:::
:::info This paper is available on arxiv under CC BY 4.0 DEED license.
:::
\
Potrebbe anche piacerti

Analyst Ignores Bitcoin (BTC) Price Crash Narratives, Points to Hidden Bull Signals That May Matter More

UK and US Seal $42 Billion Tech Pact Driving AI and Energy Future
