

Bitcoin Hyper Not Far from $20M, Whales Keep Buying: See What This $BTC Layer-2 Plans
To the uninitiated, Bitcoin and crypto are synonymous – and it’s only fair, given that the granddaddy of all crypto has been the face of the industry ever since it burst onto the scene a few years back.
Since 2020, Bitcoin has generated over 1,500% in returns. Basically, crypto is so much about Bitcoin.
All the chatter in crypto, since forever, has been around Bitcoin, from stories of people misplacing their cold wallets with $BTC bought at $10, now worth over $110K, to headlines about its dominance.
Until now, Bitcoin has really only been looked at as an investment vehicle, but a new contender is aiming to redefine what the Bitcoin blockchain can do. Enter Bitcoin Hyper ($HYPER).
$HYPER is a new cryptocurrency project that aims to turbocharge Bitcoin with Solana-like speed, scalability, and Web3 support. It’s about finally bringing digital gold up to true gold blockchain standards.Currently in presale, $HYPER has already accumulated over $17.5M from early investors, including $30.5K from crypto whales just yesterday.
Read on as we unpack $HYPER in detail, explaining why it’s arguably the best crypto to buy in 2025.
Bitcoin’s Place in Crypto & Prevalent Problems
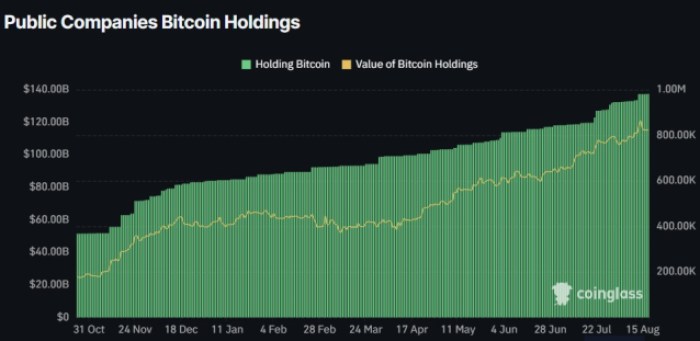
The total public Bitcoin holdings are now $116B, whereas other top altcoins like Ethereum and Solana only have around $14B and $3B in public company treasuries, respectively.
That’s a huge gap and a clear indicator of Bitcoin’s place in the industry.
Think of it like creating a fruit market. It would only be fair that mango, the king of all fruits, be put as the face of the market and given the largest proportion in any index fund for that fruit-based market.
That said, mango isn’t the be-all and end-all of the fruit economy, and other fruits are just as vital.
Similarly, while Bitcoin dominates the space in terms of popularity and online chatter, other blockchains like Ethereum and Solana are actually doing the work to form the basis of the crypto infrastructure.
It’s very important to separate crypto from just a returns perspective or investment avenue, and to also see what it truly stands for: a hedge against macroeconomic instability, decentralization, anonymity, and simply offering users a much better alternative to today’s handicapped traditional fiat banking system.In that regard, Ethereum and Solana dominate the DeFi space, the Web3 ecosystem, and the altcoin launchpad sector. It’s easy to argue they’re just as important to the core blockchain fundamentals of the industry as Bitcoin is.
However, Bitcoin will remain the granddaddy, and it’s understandable (but maybe not) that with so many returns and its mainstream presence, it has fallen off in terms of innovation.
Bitcoin’s Technical Stagnation: The Problem Waiting to Be SolvedBitcoin is currently the 29th fastest blockchain in the world, with the ability to process just 7 transactions per second.
Compare that with Solana, which can theoretically process 65K transactions per second, and you can see why Bitcoin is nowhere in developer conversations.

Its scripting language is deliberately restrictive, making it nearly impossible to build complex applications directly.
As a result, almost every talented developer has pivoted toward Ethereum, Solana, and other smart contract platforms where they can build and experiment freely.
In short, Bitcoin is financially dominant but technically stagnant.
Now, here’s the kicker: In any business, if you can identify a true, industry-wide problem and solve it, success is all but guaranteed. That’s why it’s important we have a conversation around Bitcoin Hyper ($HYPER).
Bitcoin Hyper Brings Solana’s Performance & Programmability to Bitcoin
Bitcoin Hyper is building a brand-new Layer 2 solution for Bitcoin that will integrate with the Solana Virtual Machine (SVM).
Unlike the very popular Ethereum Virtual Machine (EVM), the SVM is capable of executing thousands of transactions in parallel – the only condition being they’re not related to each other.
This becomes $HYPER’s core problem-solving bottom line, as it essentially cranks up Bitcoin’s sluggish speeds to modern blockchain standards.
Most importantly, despite this being a Layer 2 solution – with transactions happening off-chain, almost like on a sidechain – there’s no compromise in security, which Bitcoin’s Layer 1 is widely regarded for.Bitcoin Hyper simply batches the results of its transactions and submits a summary to the Bitcoin mainchain, ensuring both lightning-fast execution and Bitcoin’s native security.
$HYPER’s Canonical Bridge Ensuring Seamless Interaction with New BTC Web3
Hyper’s SVM integration will also allow developers to build smart contracts and decentralized applications on the network.
This brings in an entirely new layer of use cases for developers and users on Bitcoin: think high-speed DeFi trading, NFTs, DAOs and governance, lending, staking, swapping, and blockchain gaming.

Even better, Bitcoin Hyper makes it incredibly seamless for users to interact with this SVM-powered Web3 environment.
- All you have to do is submit your Layer 1 Bitcoin into Hyper’s non-custodial, decentralized, canonical bridge.
- It will then verify the transaction, lock your original Layer 1 BTC, and then mint an equivalent amount of BTC tokens on Hyper’s Layer 2.
- These tokens are compatible with Layer 2 and can be used to interact with the newly unlocked Bitcoin Web3 ecosystem.
Don’t Miss the $HYPER Presale: Early Investors Reap the Biggest Rewards
Let’s fully understand Bitcoin Hyper’s potential. Consider why people buy different altcoins.
People buy Ethereum, Solana, and XRP for what they mean to the crypto infrastructure, not solely because they could 10x or 100x in the next five or ten years.
However, people buy Bitcoin because of what they believe crypto as a whole could become in the next five to ten years.
While this is a positive, since Bitcoin is the face of the industry, it also shows that there’s very little native reasoning to buy Bitcoin itself from a utility standpoint.
That is what Bitcoin Hyper is changing. It can actually crank up Bitcoin’s real-world utility, essentially igniting a fire under its belly, while also potentially becoming one of the next cryptos to explode.Currently in presale, $HYPER has already raised over $17.5M in early investor funding, with each token priced at just $0.012955.
This is a golden opportunity, as you might never see Hyper at such a low price again, with a listing just around the corner.

According to our Bitcoin Hyper price prediction, the token could reach $0.32 by the end of 2025, which would represent a staggering 2,300% return on your investment if you get in now.
If you need help with the purchase process, check out our step-by-step guide on how to buy Bitcoin Hyper.
Visit Bitcoin Hyper’s official website to learn more about what it could truly mean for Bitcoin and the broader crypto economy.
Disclaimer: Crypto investments are highly risky. This article is not financial advice, so kindly always do your own research before investing.
Authored by Krishi Chowdhary, Bitcoinist — https://bitcoinist.com/bitcoin-hyper-not-far-from-20m-as-whales-keep-accumulating
Potrebbe anche piacerti

Trump-backed WLFI launches AgentPay SDK open-source payment toolkit for AI agents

Summarize Any Stock’s Earnings Call in Seconds Using FMP API

